
순환 신경망(RNN)이란 무엇인가?
RNN(Recurrent Neural Network)은 피드포워드 신경망과 다르게 내부의 메모리를 이용해 입력과 출력을 시퀀스 단위로 처리하는 시퀀스 모델이다.
시퀀스란 순서대로 이어진 것을 말한다. 시계열 데이터 같은 경우는 시간의 흐름에 따른 데이터이기 때문에 시퀀스 데이터이고 자연어 같은 경우는 문장은 각 단어들이 연속해서 이루어진 것이므로 시퀀스 데이터라고 할 수 있다.
이와 같이 시퀀스들을 처리하기 위해 고안된 모델을 시퀀스 모델이라고 하는데, RNN은 가장 기본적인 모델이라고 할 수 있다.
RNN 구조
일반적인 피드포워드 신경망은 은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로 전달한다. 하지만 RNN은 출력층 방향으로 전달하면서 동시에 다시 은닉층 노드의 다음 계산의 입력으로 보낸다.
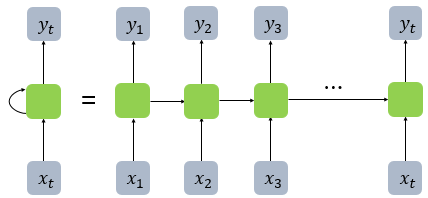
위 그림에서 x는 입력층의 벡터이고 y는 출력층의 벡터이다. 초록색 부분은 은닉층에 해당하는데 활성화 함수를 통해 결과를 출력층으로 보냄과 동시에 다음 은닉층의 입력으로 보낸다.
초록색 부분을 메모리 셀 또는 RNN셀이라고 부르며 이 셀은 은닉층의 이전의 값을 기억하는 일종의 메모리 역할을 수행한다.
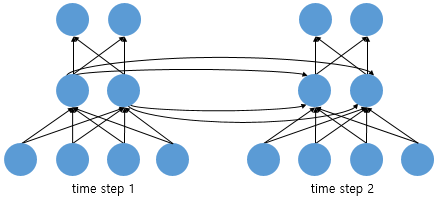
위의 그림은 뉴런의 이동 경로를 나타낸다. 중간 부분인 은닉층을 보면 time step 1인 은닉층이 출력층으로 이동함과 동시에 time step 2의 은닉층으로도 이동한다. 위 그림에서 볼 수 있듯이, RNN은 입력과 출력의 길이를 다르게 설계 할 수 있기 때문에 다양한 용도로 사용할 수 있다.
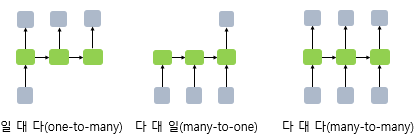
위 그림은 입력과 출력의 길이에 따라서 달라지는 RNN구조이다.
one-to-many 모델은 하나의 이미지 입력에 대해서 사진의 제목이나 설명을 예측하는 작업에 사용될 수 있다. many-to-one 모델은 여러 단어들의 입력에 대해서 2진분류를 하는 작업에 사용될 수 있다. many-to-many는 여러 단어들의 입력에 대해서 번역이나, 챗봇 같은 작업에 사용될 수 있다. 참고로 one-to-one은 시퀀스를 처리하지 않는다.
RNN 수식
RNN의 계산은 어떻게 이루어지는지 보자
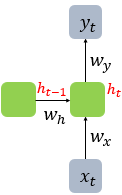
현재시점 $t$에 대해서 입력을 $x_t$, 은닉상태를 $h_t$, 출력을 $y_t$라고 가정할 때, 은닉층의 $h_t$를 계산하기 위해서는 두개의 가중치를 가지게 된다. 하나는 입력층에서 온 가중치 $W_x$이고 다른 하나는 이전 시점 $h_{t-1}$에서 오는 가중치 $W_h$이다. 이를 식으로 표현하면 다음과 같다.
$h_t = tanh(W_xx_t + W_hh_{t-1} + b)$
$y_t = f(W_yh_t + b)$
위의 식에서 각 가중치 $W_x$, $W_h$, $W_y$의 값은 하나의 층에서는 모든 시점에서 값을 동일하게 공유한다. 만약 은닉층이 2개 이상이라면 각 은닉층에서의 가중치는 다르다.
여기서 $h_t$에서의 $tanh$는 은닉층에서 많이 사용하는 활성화 함수이고, $y_t$에서의 $f$는 출력층의 활성화 함수이다. 사용하려는 task에 맞게 $sigmoid$ 또는 $softmax$가 될 것이다.
RNN 구현
RNN은 keras를 사용하여 구현이 가능하다.
from tensorflow.keras.layers import SimpleRNN
model.add(SimpleRNN(hidden_units, input_shape=(timesteps, input_dim)))
여기서 hidden_units는 은닉층의 개수를 말한다.
RNN Layer는 (batch_size, timesteps, input_dim)크기의 3차원 텐서를 입력으로 받는다.
아래 코드를 보자.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import SimpleRNN
model = Sequential()
model.add(SimpleRNN(3, input_shape=(2,10)))
model.summary()
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn_5 (SimpleRNN) (None, 3) 42
=================================================================
Total params: 42
Trainable params: 42
Non-trainable params: 0
_________________________________________________________________
입력이 (2, 10)인데 batch_size는 어디갔냐 하면 아직 지정을 해주지 않은 것이다. batch_size는 모델을 만들기 전에 이미 만들어져 있는 경우가 많다. 즉, 모델에 실제 입력으로 넣는 데이터는 3차원이 맞다. 하지만 배치사이즈 지정을 안해준 것이다. 안해줘도 모델이 알아서 계산을 해주기 때문이다. 출력값이 (batch_size, output_dim) 크기의 2차원 텐서일 때, output_dim은 hidden_units의 값과 같다. 여기서는 batch_size를 알 수 없으므로 (None, 3)이 출력된다.
아까 위해서 사용자 임의로 원하는 출력값을 설정할 수 있다고 했었다. 메모리 셀의 최종 시점의 은닉 상태만 리턴하고 싶으면 (batch_size, output_dim)형태의 2차원 텐서로 반환된다. 이게 지금 바로 위의 코드이다.
그렇다면, 메모리 셀의 각 시점의 은닉 상태값을 전부 리턴하고 싶으면 어떻게 해야할까?
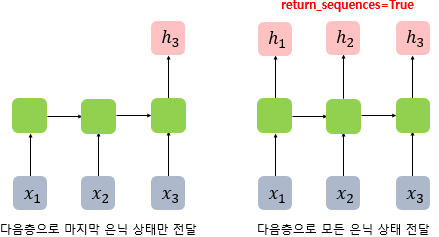
RNN Layer에 return_sequences=True를 설정하면, (batch_size, timesteps, output_dim)크기의 3차원 텐서를 반환하게 된다.
마지막 은닉 상태만 전달하도록 하면 many-to-one 모델을 만들 수 있고, 모든 시점의 은닉상태를 전달한다면 many-to-many 모델을 만들 수 있는 것이다.
아래 코드를 보자
model = Sequential()
model.add(SimpleRNN(3, batch_input_shape=(8, 2, 10), return_sequences=True))
model.summary()
Model: "sequential_7"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn_7 (SimpleRNN) (8, 2, 3) 42
=================================================================
Total params: 42
Trainable params: 42
Non-trainable params: 0
_________________________________________________________________
이번에는 batch_size까지 포함해서 (8, 2, 10)을 input으로 넣고 return_sequences=True로 한 상태이다.
timesteps인 2을 포함해서 출력값을 보면 (8, 2, 3)인 3차원 텐서가 반환된 것을 알 수 있다.
RNN의 장단점
RNN은 모델이 간단하고 어떤 길이의 sequential 데이터라도 처리할 수 있다는 단점이 있다. 하지만 벡터가 순차적으로 입력되기 때문에 병렬화가 불가능하다. 또한 기울기 소실 문제가 존재한다.
기울기 소실 문제를 해결하기 위해 나온 모델이 LSTM이다.
LSTM의 설명은 여기에서 볼 수 있다.
댓글남기기