
자연어처리-4 Attention Mechanism
지난시간에 seq2seq모델에 대해서 포스팅 했었다. 여기
이번 시간에는 자연어처리 시리즈 4번째인 어텐션 메커니즘에 대해 알아보자.
seq2seq모델의 한계
seq2seq모델에 대해서 잠깐 복습해보자. 입력 시퀀스가 들어오면 인코더를 거쳐서 고정된 길이의 컨텍스트 벡터를 내보낸다.
이 벡터는 디코더로 들어가서 디코더에서 계산을 거쳐서 최종 출력 시퀀스를 내보낸다.
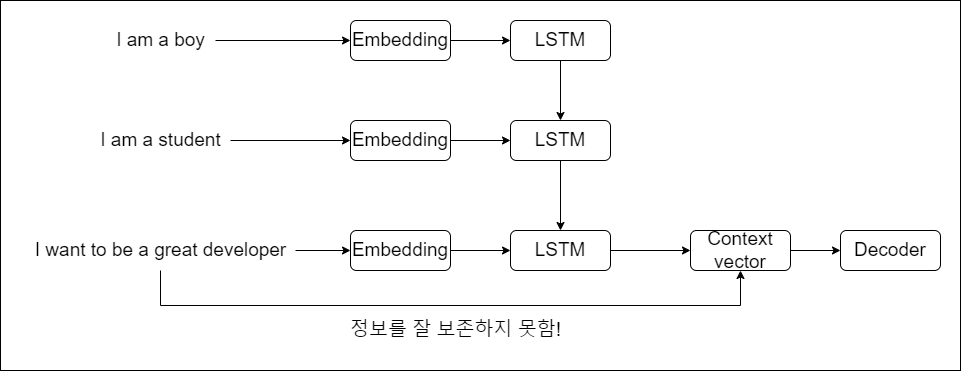
하지만 seq2seq모델의 문제는 고정된 길이의 컨텍스트 벡터를 내보내기 때문에, 긴 시퀀스의 입력이 들어오게 되면 정보를 잘 압축하지 못한다.
그림에서 I want to be a greate developer라는 긴 문장이 들어왔을 때, 고정벡터로 압축하는데 부담이 된다는 이야기다.
이걸 해결하기 위해 seq2seq모델에 어텐션 메커니즘이 합쳐진 모델이 등장하게 된다.
Attention 메커니즘
어텐션 메커니즘은 고정된 크기의 벡터(컨텍스트 벡터) 하나의 입력 시퀀스의 정보를 다 압축시켜야 하는 부담을 덜기 위해서 디코더에서 예측을 할 때, 인코더의 컨텍스트 벡터 뿐 아니라 인코더의 매 시점 은닉 상태들을 모두 사용하자는 개념이다.
구체적으로, 어텐션 메커니즘을 다음을 가정한다.
디코더가 단어 X를 출력하기 직전의 디코더 은닉 상태는, 인코더가 입력 시퀀스 X와 연관이 깊은 단어를 읽은 직후의 인코더 은닉상태와 유사할 것이다.
예를 들어보자면 출력 시퀀스의 단어인 ‘학생’의 은닉상태는 입력 시퀀스의 단어인 ‘student’의 은닉상태와 연관성이 깊다고 가정하는 것이다. 따라서 인코더가 ‘학생’이라는 단어를 입력받은 직후의 은닉상태에 조금더 ‘집중(Attention)’ 하면, 조금 더 좋은 품질의 모델을 만들지 않을까?라는 생각에서 도출된 개념인 것이다.
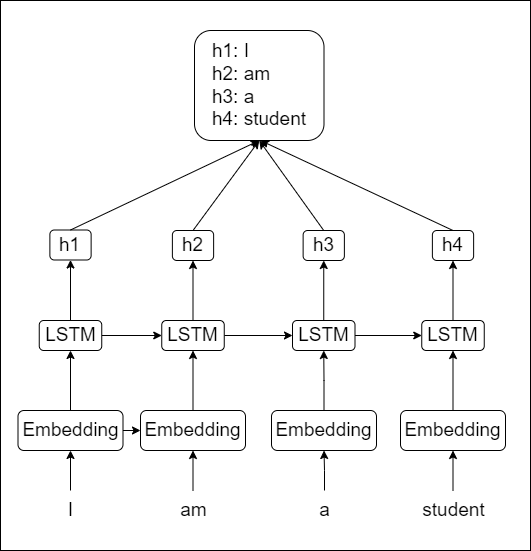
위 그림은 인코더의 각 시점의 은닉상태를 하나로 합쳐놓은 것을 뜻한다. 물론 저 상태 그대로 디코더에 들어가는 것은 아니다. 디코더는 모여있는 저 값을 참고를 해서 계산을 하는 것이다.
Attention 동작과정
seq2seq에 어텐션을 적용한 모델의 디코더는 다음과 같은 순서로 단어를 예측한다.
-
어느 시점의 인코더 은닉상태에 더 ‘집중’해야 하는지 찾기 위해, 현재 디코더의 은닉상태와 매 시점 인코더의 은닉상태들 간의 ‘유사도’를 계산한다.
-
이 유사도를 확률형태로 바꾸고, 그 값에 따라 인코더 은닉상태들의 가중합을 구해 ‘보정된 컨텍스트 벡터’를 구한다.
-
‘보정된 컨텍스트 벡터’와 디코더 은닉상태를 이용해 다음 단어를 예측한다.
이렇게 하면 인코더의 마지막 은닉상태 뿐만 아니라 인코더의 매 시점 은닉상태들이 모두 디코더로 넘어가므로, 입력시퀀스 길이에 따른 손실되는 정보가 거의 없다. 또한 초기 시점의 인코더 은닉상태와 후반 시점의 인코더 은닉상태가 동등하게 확률의 형태로 전달되므로 기울기 소실/폭발 현상을 줄일 수 있다.
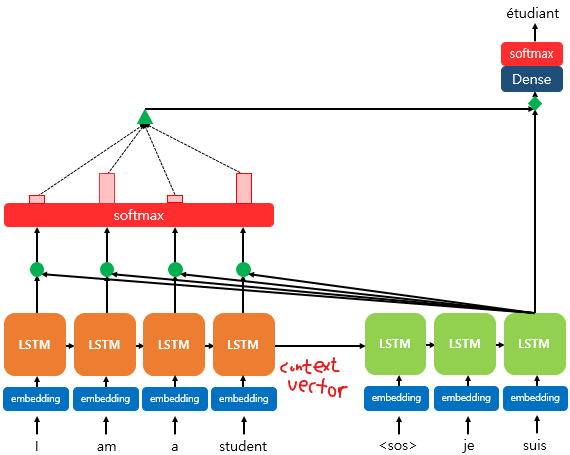
위 그림은 디코더의 마지막 LSTM에서 출력 단어를 예측할 때 어텐션 메커니즘을 사용하는 대략적인 예시이다.
마지막 LSTM의 히든상태와 매 시점 인코더의 은닉상태들 간의 유사도를 계산한다.
그리고 이 유사도를 softmax함수를 통해서 확률값으로 변환한다.
그림에는 안나와 있지만 마지막으로 이 확률값과 인코더 은닉상태들의 가중합을 구해서 그림에서 초록색 삼각형에 해당하는 보정된 컨텍스트 벡터를 구한다.
최종적으로 보정된 컨텍스트 벡터와 마지막 LSTM의 은닉상태로 최종 output을 낸다.
한가지 주의할 점은 맨 처음 디코더 셀에는 seq2seq모델과 같이 인코더의 마지막 은닉상태인 컨텍스트 벡터가 들어간다
이전의 디코더 셀에서도 같은 방식으로 동작한다!
보정된 컨텍스트 벡터를 구하기 위해서 Score Funtion, attention distribution, attention value를 구하는 3가지 과정을 거친다. 각각 어떻게 계산되어 지는지 알아보자.
과정1: Attention Score
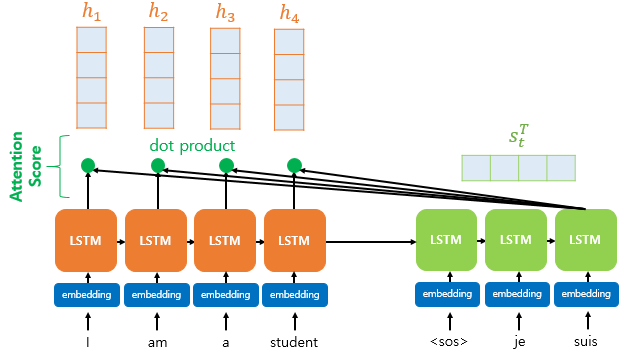
Attention Score는 디코더의 시점 $t$에서 새로운 단어를 예측하기 위해 디코더의 은닉상태 $s_t^T$와 인코더의 은닉상태 $h_1$~$h_t$들이 얼마나 유사한지를 계산하는 점수이다.
위 그림은 디코더의 시점 t에서의 은닉상태인 $s_t$와 인코더의 은닉상태인 $h_t$의 Attention Score를 구하는 과정을 보여준다.
$h_1 … h_t$는 $t$ 시점에서 인코더의 은닉상태이고 $s_t^T$는 t시점의 디코더 은닉상태를 나타낸다. $T$는 $s_{t-i}$부터 $s_t$의 합?이라고 생각하면 된다.(이전 시점의 은닉상태도 포함하고 있으므로)
그림에서도 알 수 있듯이 인코더의 모든 은닉상태에 유사도를 구하는 것이 목표이므로 내적(dot product)한다. 결과는 스칼라값이 나온다.
수식으로는 $e^t = [s_t^Th_1 + s_t^Th_2 … + s_t^Th_t]$ 와 같이 나타낼 수 있다.
과정2: Attention Distribution
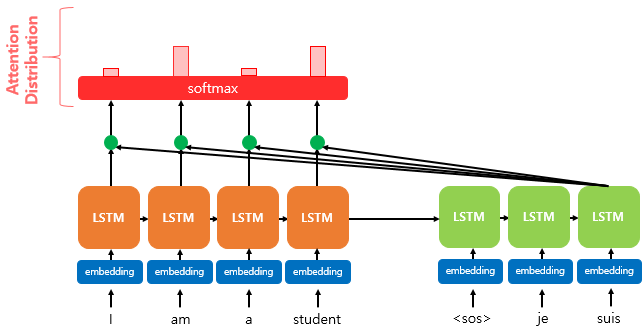
위에서 얻는 Attention Score $e^t$에 softmax함수를 적용해서 모든 값의 합이 1이 되는 Attention Distribution을 얻는다.
수식으로는 $\alpha^t = softmax(e^t)$ 와 같이 나타낸다. softmax를 통해서 나온 값을 Attention Weight(어텐션 가중치)라고 한다. 즉, 학습과정에서 최적화 된다.
과정3: Attention Value
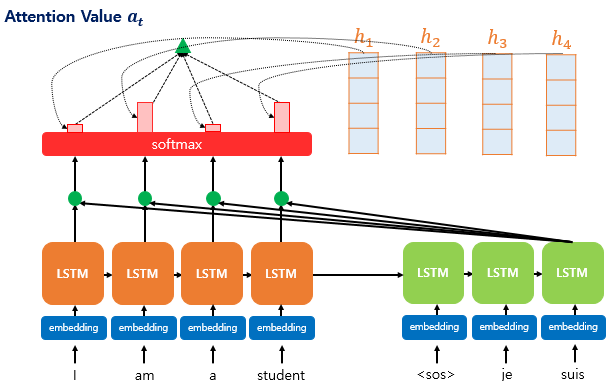
최종적으로 위에서 구한 Attention Weight와 인코더의 각 은닉상태를 가중합하여 최종적인 Attention Value $a_t$를 구한다.
식으로는 $a_t = \sum_{k=1}^{N} \alpha_i^t h_t$ 로 나타낼 수 있다.
결론적으로 $a_t$ 위에서 말한 보정된 컨텍스트 벡터가 된다.
Query, Key, Value
처음 어텐션 메커니즘을 공부하면 제일 헷갈리는 단어가 Query, Key, Value이다.
어텐션 메커니즘의 동작 과정을 이 세단어로 표현이 가능하다.
query 데이터베이스를 공부하면서 많이 들어봤을 것이다. 데이터베이스로부터 데이터를 요청하는 것이 query이다.
어텐션도 비슷한(?) 맥락이다. 어텐션에서의 query는 디코더의 은닉상태의 값을 요청한다고 생각하면 쉽다. key와 value는 인코더의 은닉상태를 뜻한다.
아래 그림을 한번 보자.
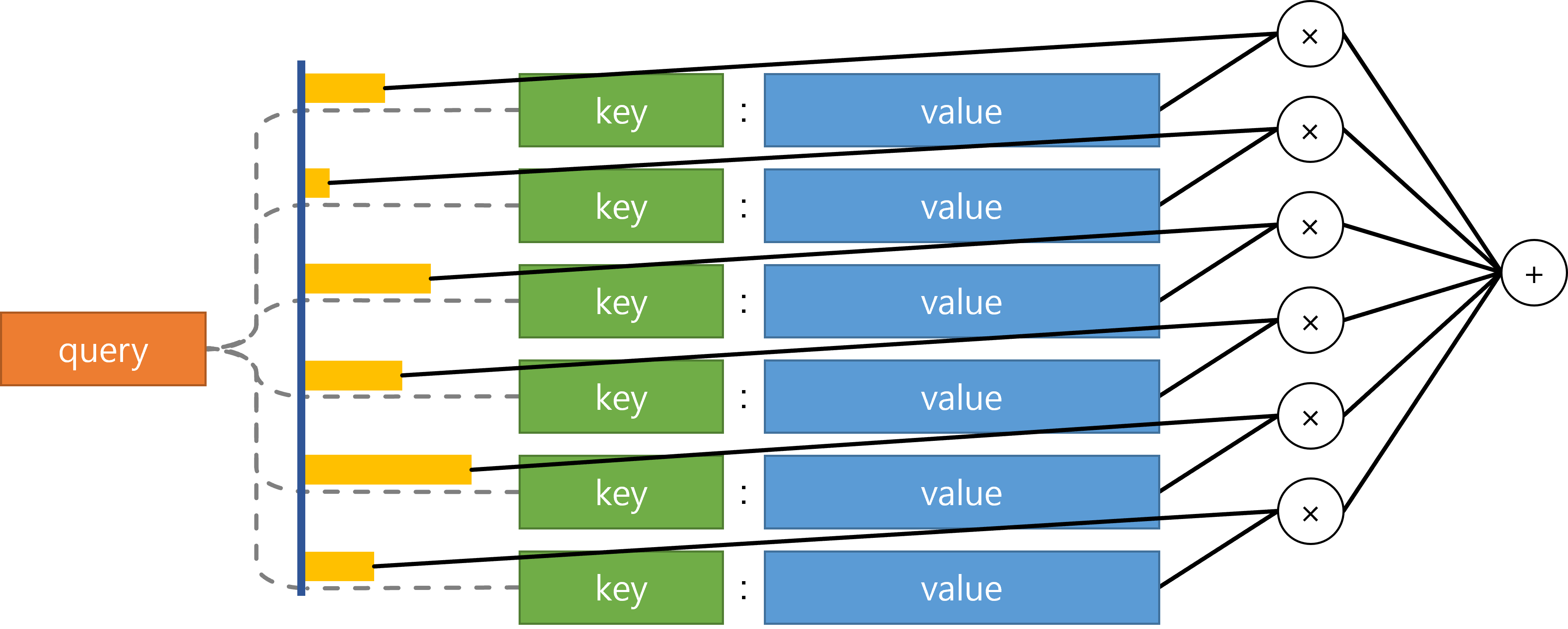
query와 각 key들 간의 유사도를 구한다. 그리고 softmax를 통해 확률분포로 변환하고 이 분포를 이용해 각 value들의 가중합을 구한다. 즉, 어텐션 메커니즘은 주어진 query에 대해 어떤 value에 더 ‘집중’할지를 결정하는 것이다.
최종단계
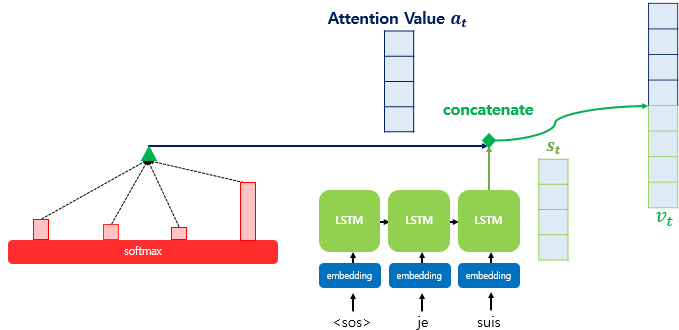
위에서 구한 Attention Value $a_t$를 디코더의 $t$시점의 은닉상태 $s_t$와 concat한다.
수식으로는 $v_t = [a_t;s_t]$ 로 정의한다. 이렇게 만들어진 벡터 $v_t$는 위에서 말한 보정된 컨텍스트 벡터이다.
$v_t$는 디코더의 은닉상태의 정보 외에도 인코더에서 모든 은닉상태를 고려한 정보를 포함하고 있기 때문에 긴 시퀀스의 입력이 들어와도 정보를 크게 잃지 않는다. 따라서 예측값 $\hat{y}_t$를 더욱 정확한 성능으로 반환할 수 있다.
Neural Machine Translation by Jointly Learning to Align and Translate
본 논문은 Attention 메커니즘이 처음 등장한 논문이다.
논문에서는 보정된 컨텍스트 벡터를 바로 출력층으로 보내지 않고 연산을 한번 더 추가하였다.
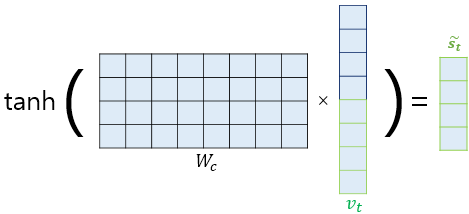
가중치 행렬과 보정된 컨텍스트 벡터를 곱한후 하이퍼볼릭탄젠트 함수를 지나서 새로운 벡터 $\bar{s}_t$를 얻는다.
수식으로 표현하면 $\bar{s}_t$ = $tanh(W_c[a_t;s_t]+b_c)$로 정의된다.
$a_t;s_t$는 concat이라는 뜻이고 보정된 컨텍스트 벡터를 나타낸다.
마지막으로 최종 예측은 $\hat{y}_t$ = $softmax(W_y\bar{s}_t) + b_y$로 계산된다.
Attention 종류
seq2seq + attention 모델에 쓰일 수 있는 다양한 어텐션 종류가 있다. 지금까지 포스팅 한 것은 dot-product attention이다. 따라서 루옹(Luong)어텐션이라고도 불린다. 이것들의 차이는 단지 어텐션 스코어를 구하는 방식의 차이이며 메커니즘 자체는 거의 비슷하다.
| 이름 | 식 | 출처 |
|---|---|---|
| content-based attention | $f(s,\,h) = \displaystyle \frac{s^T h}{||s|| \cdot ||h||}$ | Graves, 2014 |
| additive attention (Bahdanau attention) |
$f(s,\,h) = V^T \tanh (W_1 s + W_2 h)$[^4] | Bahdanau, 2015 |
| dot-product attention (Loung attention) |
$f(s,\,h) = s^T h$ | Luong, 2015 |
| scaled dot-product attention | $f(s,\,h) = \displaystyle \frac{s^T h}{\sqrt{n}}$[^5] | Vaswani, 2017 |
댓글남기기