
Attention의 원리와 계산과정(완전 쉬움!)
기존 Attention 포스팅에서 부족한 부분을 추가 설명하는 포스팅입니다.
사전지식
- 특정 정보를 가진 텐서는 Weight Matrix를 통과해도 정보는 보존된다.
- 각각 다른 정보를 가진 텐서A와 텐서B를 Weighted sum을 하면 두 정보 중에서 Weight가 큰 쪽의 정보를 더 많이 갖고 있는다.
텐서의 합이 1이라고 가정하고, 텐서A의 값은 0.88이고 텐서B의 값은 0.12 일 때 더해진 텐서C의 정보는 텐서A의 정보 88% 텐서B의 정보 12%를 가지고 있다.
- 텐서끼리 내적(Inner Product) 하게 되면 비슷한 정보들끼리는 값이 크게 나오고, 상관없는 정보들 끼리는 값이 작게 나온다.
벡터 공간 내 거리가 비슷할 수록 값이 크게나오고, 거리가 멀 수록 값이 작게나온다.
A[2, 3], B[4, 5]; 같은 1사분면 벡터 => (2x4)+(3x5) = 23
A[2, 3], B[-5, 2]; 다른 사분면 벡터 => (2x-5)=(3x2) = -4
Query와 Key의 연산
쿼리 텐서 한개와 키 텐서 4개로 예를 들어보겠다. 쿼리 텐서는 키 텐서 4개와 각각 내적을 한다.


이 쿼리와 키의 내적 연산의 의미는 쿼리와 가장 비슷한 위치에 있는 키 벡터가 뭔지 알아내는 것이다. 위 그림에서는 키의 세 번째 텐서가 가장 유사하다는 의미이다.
이제 내적한 값들은 exp연산을 통해 전부 양수로 만들어 주고, 각각의 값을 전체 Weight의 합으로 나눠서 아래 그림처럼 전부 양수이고 Weight의 합이 1로 만들어준다.
즉 이 연산은 Softmax 연산을 수행한 것이다.

이제 이 키 값은 쿼리와 키의 유사한 정도를 비율로 해서 정보의 혼합이 이루어진 것이다. 여기까지가 쿼리와 키의 연산의 의미이다.
Value의 연산
쿼리와 키의 유사도 연산이 수행되면 벨류와 곱해져서 Weighted Sum을 수행해서 최종적으로 연관있는 텐서 값이 나오게 된다.
Weighted Sum의 결과값은 이전에 수행된 텐서들의 정보를 다 가지고있게 된다. 벨류를 곱하는 이유는 아래에서 설명하겠다.

행렬 단위의 연산
Attention 연산은 위의 연산 방식이 전부이다. 그냥 단순히 쿼리와 키의 연관도를 계산하는 것 뿐이다. 단지 계산 방법이 불필요한 정보라도
정보를 버리지 않고 어떻게든 끌고 가면서 필요한 정보만 더 집중하게 추출하는 것이다. 위의 내용은 그냥 단지 한개의 텐서의 계산방법이고 실제로는 행렬단위로 연산이 실행된다.
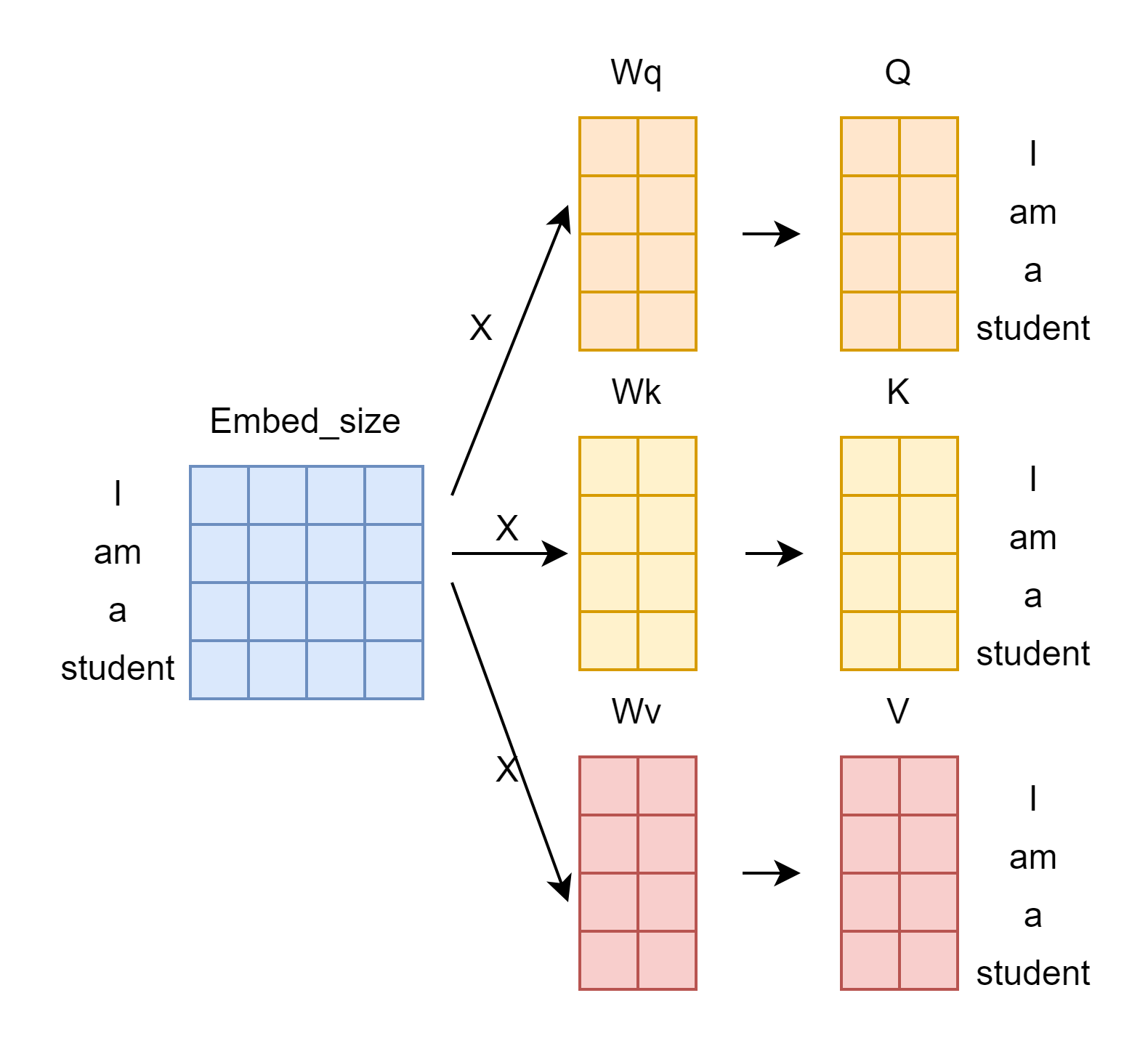
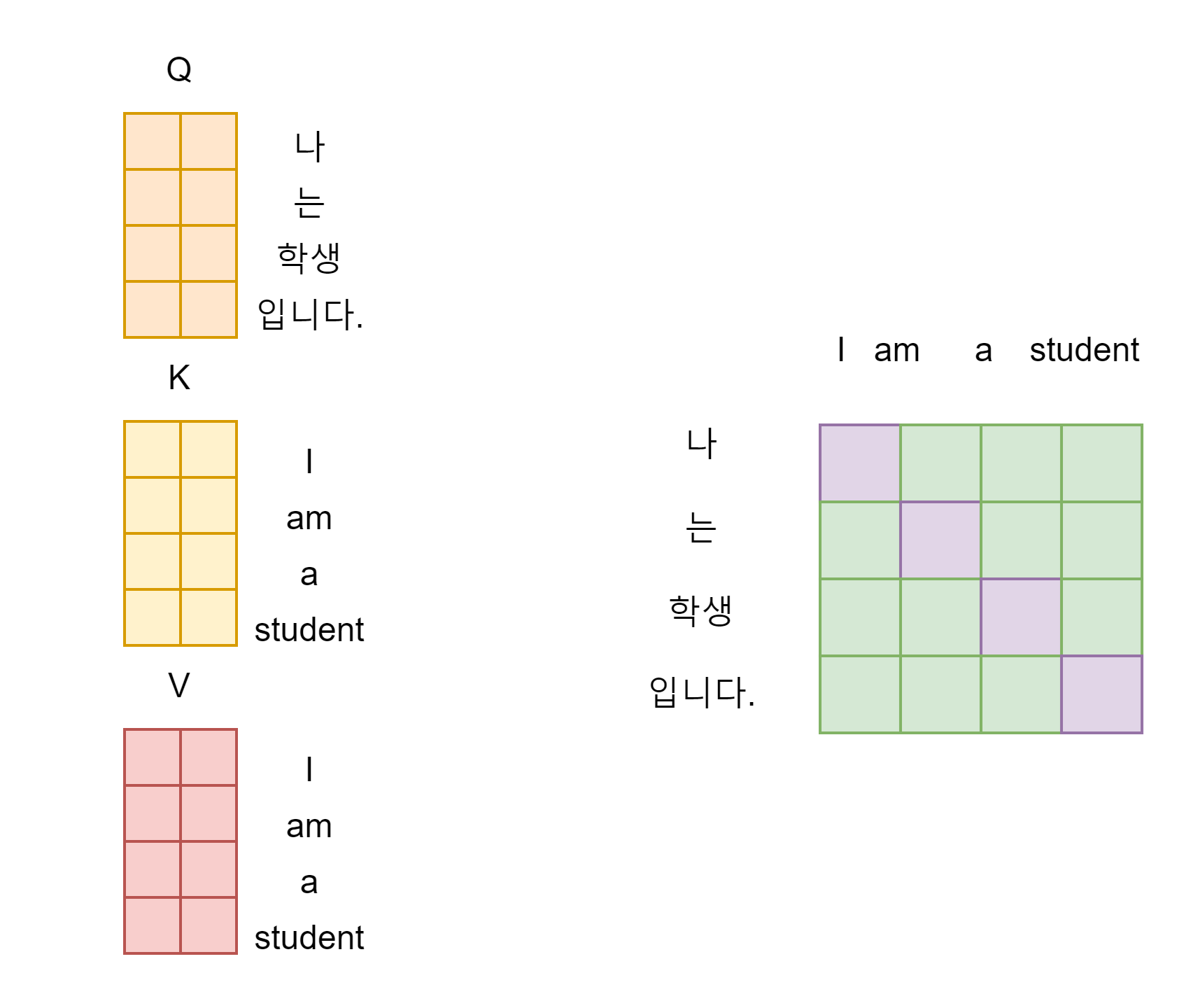
입력이 [“i”, “am”, “a”, “student”] 라는 문장이 들어간다. 이 입력은 임베딩 레이어를 거친 후에 (입력X임베딩사이즈) 크기의 텐서로 변환된다.
이렇게 변환된 텐서는 그림과 같이 q, k, v의 Weight Matrix를 지나 곱해지면서 Q, K, V 행렬이 만들어진다.
위에서 본 것처럼 이제 쿼리와 키의 내적 연산이 이루어진다.
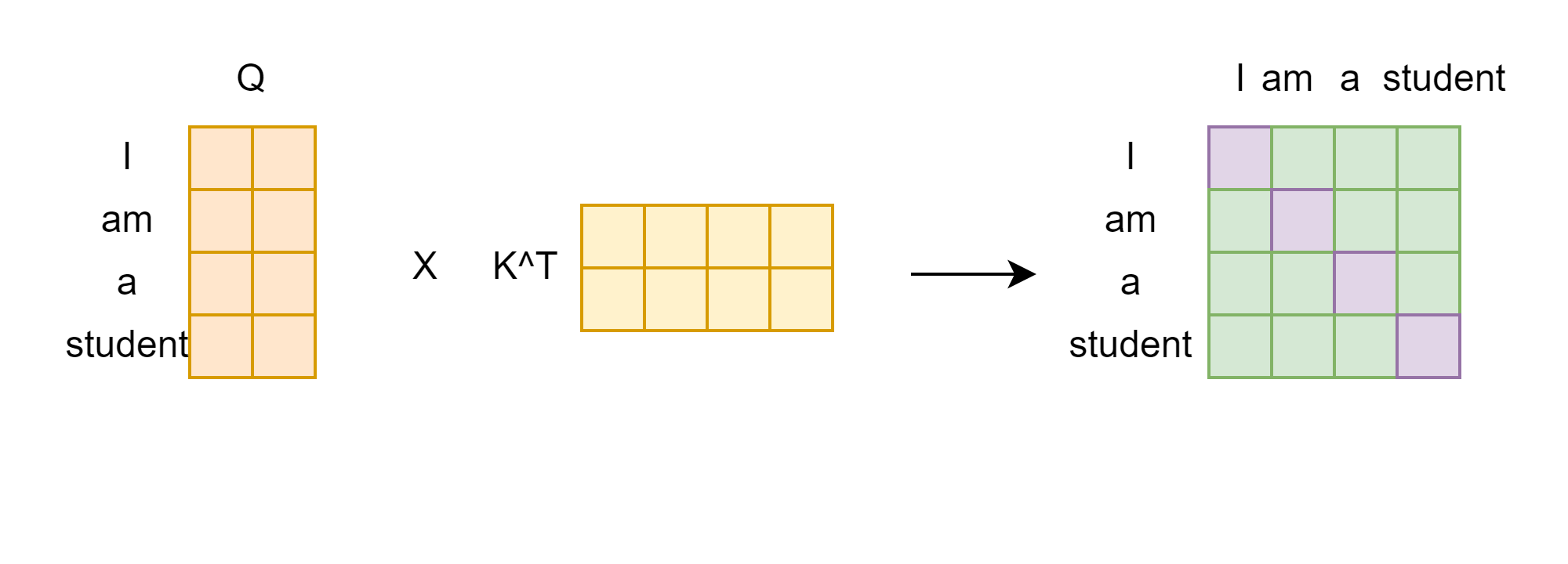
이렇게 만들어진 행렬을 Attention Score라고 한다. 이 Attention Score는 쿼리와 키의 유사한 정도를 나타낸 Matrix라고 볼 수 있다.
최종적으로 아까의 V 행렬과 곱하면 최종적으로 Attention Value가 계산된다. Attention Score와 V를 곱함으로써, Weighted Sum을 수행한다.
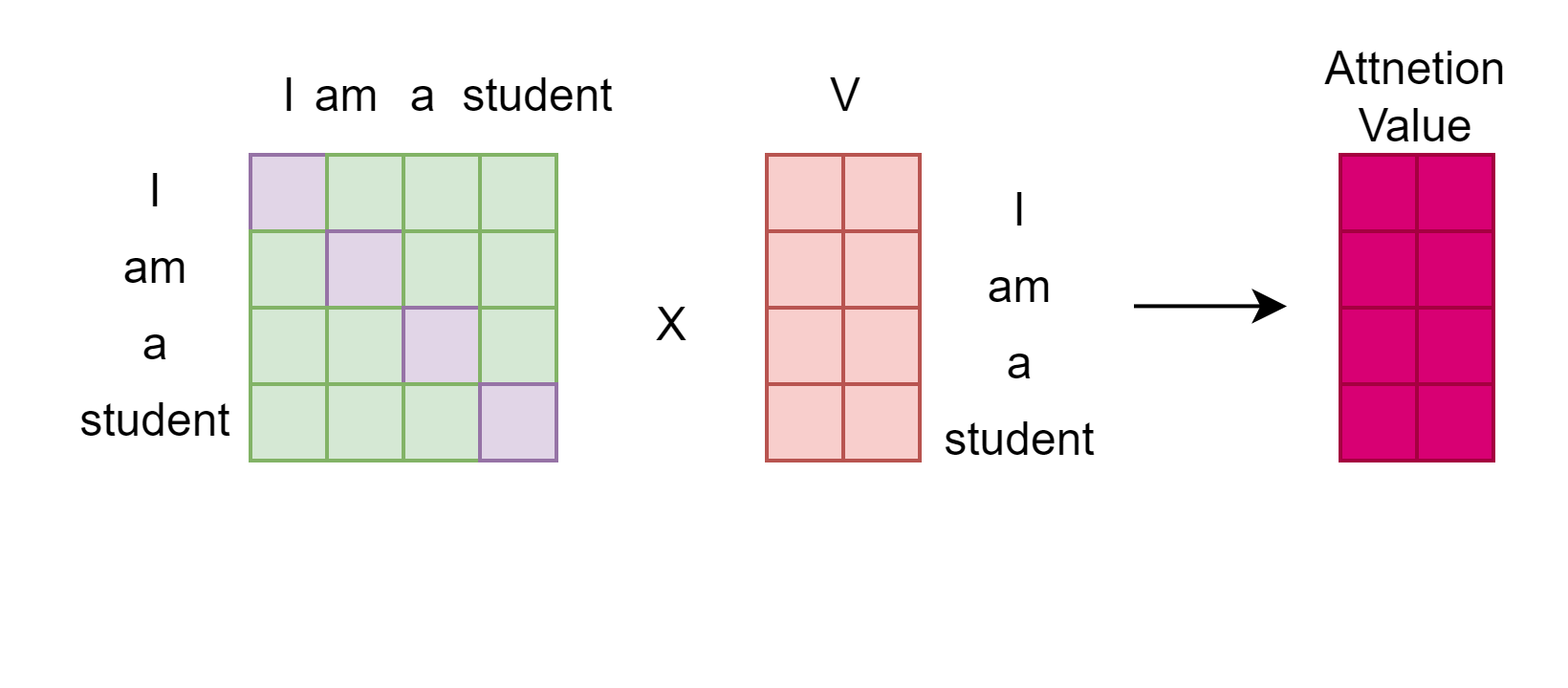
아래 사진을 보면 왜 Weighted Sum이 수행되는지 알 수 있다.
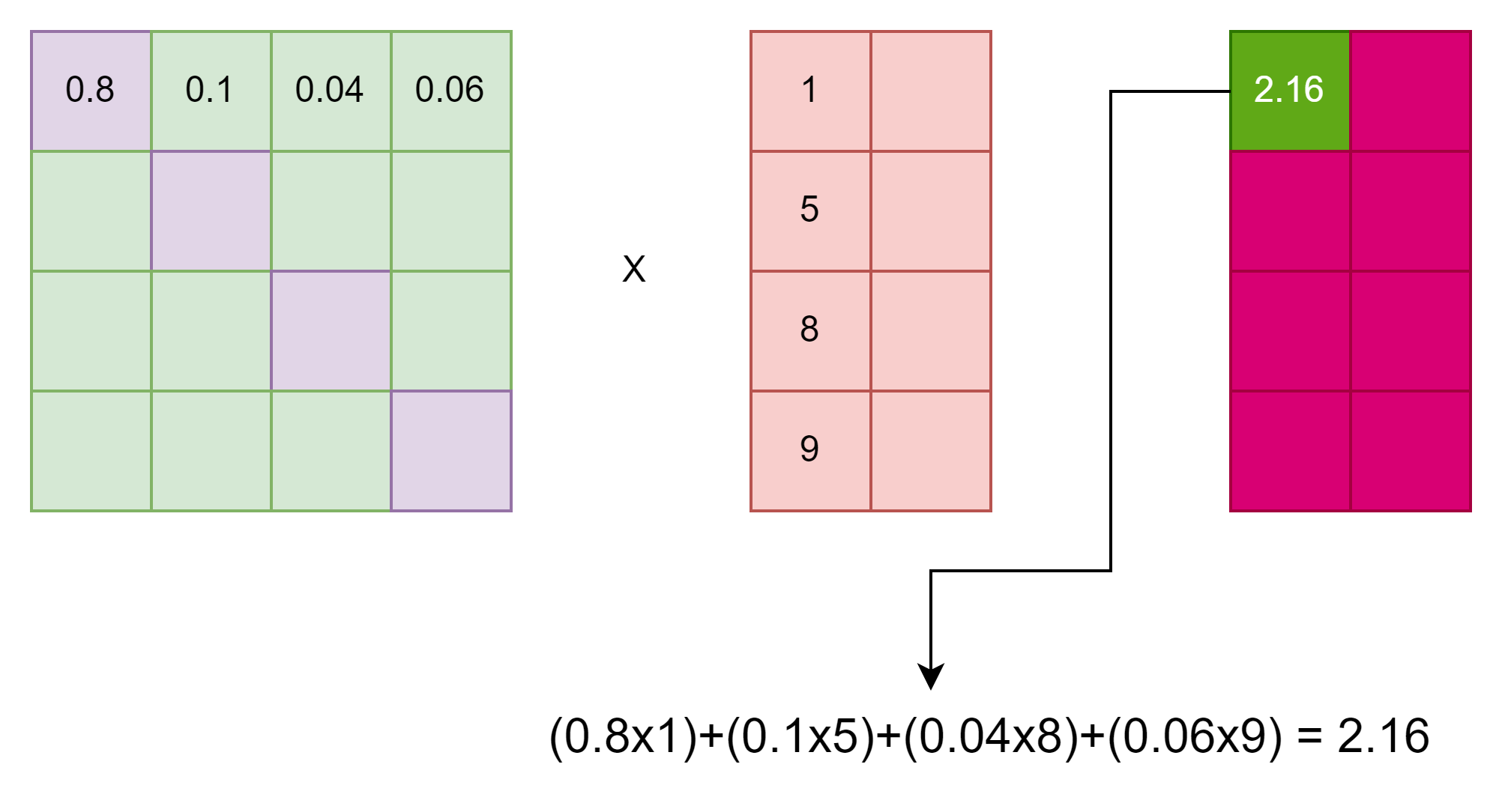
이렇게 만들어진 Attention Value의 의미를 보면, 쿼리와 키의 유사도와 함께, 어디 부분이 더 유사한 지 참고해서 벡터를 재구성 하겠다는 의미이다.
다시말하면 V 행렬에 문장의 연관성의 척도가 다 표현되어 있는 것이다.
Self-Attention & Cross-Attention
Self-Attention은 쿼리, 키, 벨류의 출처가 모두 같다. 즉, 위의 설명과 같이 [“i”, “am”, “a”, “student”] 라는 입력이 들어오면 Q, K, V가 다 동일하다.
Self-Attention은 트랜스포머의 인코더에 사용된다.
Cross-Attention은 트랜스포머의 디코더에 사용된다. 디코더에는 Attention이 두개 있는데, 첫 번째 Attention은 Self-Attention인데 Masking이 적용된 것이고,
두 번째 Attention이 Cross-Attention이다.
Cross-Attention은 Q는 디코더의 Self-Attention을 통해서 나온 Q이고 K, V는 인코더에서 넘어온 정보이다.
트랜스포머를 사용해서 번역을 한다고 가정할 때, 영어 문장이 인코더에 들어가서 문장 내의 모든 문맥 정보를 학습한 후, 일부 값을 디코더에 넘겨준다.
디코더는 한국 문장이므로, 한국 문장 내의 모든 문맥 정보를 학습한 후 Cross-Attention을 통해 한국어 문맥 정보와 영어 문맥 정보를 짬뽕해서 학습한다.
Q는 디코더에서 넘어 온 한국 문맥이고, K, V는 인코더에서 넘어온 영어 문맥이다. Attention의 기본 원리만 알면 트랜스포머는 다 이해가 가능하다.
한줄피드백
Attention은 결국 입력 문장 내에서의 유사도를 최적으로 학습하는 알고리즘이다. 이 포스팅은 Transformer의 구조에 대해서는 자세히 작성하진 않았고 오로지 Attention의 학습 목표(?)방법(?)에 대해서 작성해 보았다. 기존 Attention과 트랜스포머를 설명할 때 완벽히 이해가 되지 않았는데 어느 유튜브 영상을 보고 이해가 안되던 것이 한번에 뚫려서 한번 작성해 보았다!
댓글남기기