
오토인코더(Autoencoder)
오토인코더(Autoencoder)란?
입력층, 은닉층, 출력층으로 구성되어 있으며 단순하게 말하자면 입력을 출력으로 복사하는 방법을 배우는 신경망이다. 하지만 입력을 출력으로 바로 복사하면 신경망의 의미가 없기 때문에 은닉층의 크기를 제한하거나, 잡음을 추가하는 등 단순히 입력을 출력으로 복사하지 못하게 제한하고, 학습을 통해 소실된 데이터를 복원하고 입력 데이터의 특징을 잘 표현한 새로운 출력이 나오게 하는 것이 목표이다. 오토인코더는 라벨이 필요없는 비지도 학습중 하나이고, 자기 자신을 정답으로 출력하기 때문에 자기지도 학습이라고도 한다.
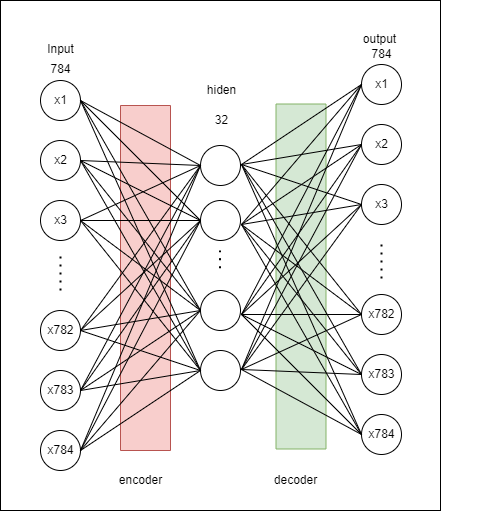
예제로 사용할 오토인코더 모델이다. 오토인코더의 종류는 매우 많지만 여기서는 가장 Basic한 Autoencoder모델을 사용하였다. Input -> hidden이 인코더부분, hidden -> output이 디코더 부분이다.
코드 구현
import tensorflow as tf
import numpy as np
from tensorflow.keras.layers import *
from tensorflow.keras.models import Model
from tensorflow.keras.models import Sequential
input_img = Input(shape=(784,)) # mnist 데이터셋은 28X28의 이미지
encoded = Dense(32, activation='relu')(input_img) # 32차원으로 축소
decoded = Dense(784, activation='sigmoid')(encoded) # 784차원으로 확장
# autoencoder 모델
autoencoder = Model(input_img, decoded) # input -> encode -> decode
# encoder 모델
encoder = Model(input_img, encoded) # input -> encode
# decoder 모델
encoded_input = Input(shape=(32,))
decoded_layer = autoencoder.layers[-1]
decoder = Model(encoded_input, decoded_layer(encoded_input)) # encode -> decode
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
encoder와 decoder는 학습된 autoencoder 모델에서 분리한 느낌이다.
decoded_layer = autoencoder.layers[-1]부분에서Dense(784, activation='sigmoid')를 하게되면 학습되지 않은 decoder가 784차원으로 단순히 확장하는 것이 된다. (결국 노이즈가 출력)
print(autoencoder.summary())
Model: "model_14"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_11 (InputLayer) [(None, 784)] 0
dense_14 (Dense) (None, 32) 25120
dense_15 (Dense) (None, 784) 25872
=================================================================
Total params: 50,992
Trainable params: 50,992
Non-trainable params: 0
_________________________________________________________________
None
# mnist 데이터 셋 load
(x_train, _), (x_test, _) = tf.keras.datasets.mnist.load_data()
print(x_train.shape)
print(x_test.shape)
# 정규화
x_train = x_train.astype(np.float32)/255.
x_test = x_test.astype(np.float32)/255.
# input shape이 784이므로 24X24이미지를 784로 평탄화 시킴
x_train_flatten = x_train.reshape((x_train.shape[0], -1))
x_test_flatten = x_test.reshape((x_test.shape[0], -1))
print(x_train_flatten.shape)
print(x_test_flatten.shape)
(60000, 28, 28)
(10000, 28, 28)
(60000, 784)
(10000, 784)
# 모델 훈련
autoencoder.fit(x_train_flatten, x_train_flatten,
batch_size=256, epochs=50,
validation_data=(x_test_flatten,x_test_flatten))
Epoch 5/50
235/235 [==============================] - 1s 4ms/step - loss: 0.1186 - val_loss: 0.1131
Epoch 10/50
235/235 [==============================] - 1s 4ms/step - loss: 0.0977 - val_loss: 0.0955
Epoch 15/50
235/235 [==============================] - 1s 4ms/step - loss: 0.0941 - val_loss: 0.0927
Epoch 20/50
235/235 [==============================] - 1s 4ms/step - loss: 0.0934 - val_loss: 0.0921
Epoch 25/50
235/235 [==============================] - 1s 4ms/step - loss: 0.0931 - val_loss: 0.0920
Epoch 30/50
235/235 [==============================] - 1s 4ms/step - loss: 0.0929 - val_loss: 0.0918
Epoch 35/50
235/235 [==============================] - 1s 4ms/step - loss: 0.0928 - val_loss: 0.0916
Epoch 40/50
235/235 [==============================] - 1s 4ms/step - loss: 0.0928 - val_loss: 0.0916
Epoch 45/50
235/235 [==============================] - 1s 4ms/step - loss: 0.0927 - val_loss: 0.0916
Epoch 50/50
235/235 [==============================] - 1s 4ms/step - loss: 0.0926 - val_loss: 0.0915
# encoding 이미지 출력
encoded_imgs = encoder.predict(x_test_flatten)
print(encoded_imgs.shape)
# encoding -> decoding 이미지 출력
decoded_imgs = decoder.predict(encoded_imgs)
print(decoded_imgs.shape)
313/313 [==============================] - 0s 660us/step
(10000, 32)
313/313 [==============================] - 0s 835us/step
(10000, 784)
import matplotlib.pyplot as plt
n = 10 # 이미지 갯수
plt.figure(figsize=(20, 4))
for i in range(1, n+1):
# 원본 데이터
ax = plt.subplot(2, n, i)
plt.imshow(x_test_flatten[i+50].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 재구성된 데이터
ax = plt.subplot(2, n, i + n)
plt.imshow(decoded_imgs[i+50].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
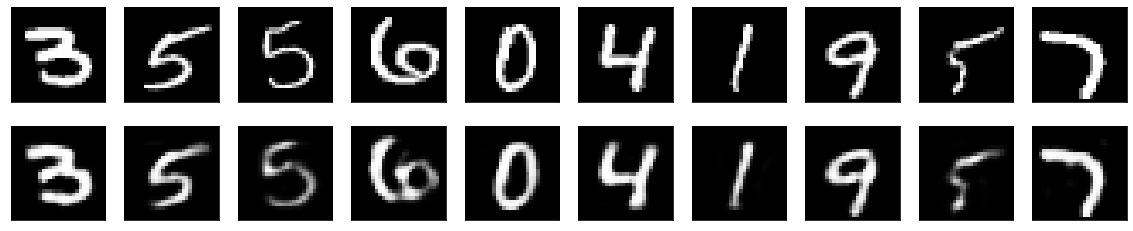
은닉층이 하나임에도 불구하고 꽤 괜찮은 결과를 볼 수 있다.
댓글남기기