
CNN을 이용해서 Mnist를 분류해보자!
이번 예제는 CNN을 이용하여 Mnist 데이터셋을 분류합니다. CNN에 대해 모르신다면 여기를 참고해 주세요!
필요한 모듈 가져오기
우선 Mnist 분류에 필요한 라이브러리들을 가져와보자.
CNN 모델에서 필요한 Layer들은 모두 keras에서 지원한다.
CNN 모델에서 Dropout이나 BatchNormalization은 생략하였다. 이 기능에 대해서 궁금한 사람들은 ChatGPT에 물어보자. 아주 친절하게 알려준다…
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Flatten
from keras.layers import Conv2D, MaxPooling2D
import matplotlib.pyplot as plt
import numpy as np
데이터 로드
Mnist 데이터셋을 불러오자. 이 데이터셋에 대해서 간략하게 말하면 0~9까지 숫자를 손으로 쓴 이미지 데이터이다. 2차원 데이터로 구성되어 있으며, 훈련데이터 60000개 테스트데이터 10000개로 구성되어 있다.
참고로 x_는 이미지, y_는 이미지에 맞는 정답이 들어있다.
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)
(60000, 28, 28)
(60000,)
(10000, 28, 28)
(10000,)
데이터 전처리
이제 이미지 데이터를 3차원으로 만들어 주고 데이터를 정규화 해주자. 훈련데이터만 3차원으로 늘려주면 모델이 정상적으로 학습은 하겠지만, predict과정에서 테스트데이터를 넣어줄 때 shape오류가 날 것이다.
3차원 데이터로 만드는 이유는 Conv2D 레이어의 입력값이 3차원만 가능하기 때문이다. Mnist 데이터셋 같은 경우 컬러이미지는 아니므로 그냥 1차원만 추가해준다.
255로 나누는 이유는 픽셀값이 0~255의 값으로 이루어져 있기 때문에 모든 값이 0~1사이의 값으로 만들어 주는 것이다. sklearn에서 제공하는 MinMaxScaler를 사용해도 상관없다.
x_train = x_train.reshape(-1,28,28,1)/255.
x_test = x_test.reshape(-1,28,28,1)/255.
이미지 출력
Mnist 데이터셋이 어떻게 생겼는지 이미로 봐보자. 2차원 데이터를 이미지로 보고 싶으면 imshow()를 사용하면 된다. 코드가 좀 복잡한데 대충 설명을 하자면..
일단 x_train데이터의 개수만큼 랜덤으로 5개의 숫자를 뽑아온다. 이게 인덱스가 될 것이다. 그 다음 for문을 돌면서 subplot으로 랜덤 인덱스에 맞는 이미지를 여러개 출력하는게 끝이다.
코드에서 볼 수 있듯이 y에는 이미지에 보여지는 숫자에 맞게 정수가 담겨있다.
random_index = np.random.randint(len(x_train), size=5)
plt.figure(figsize=(15, 15))
for i, idx in enumerate(random_index):
img = x_train[idx]
label = y_train[idx]
plt.subplot(1, len(random_index), i+1)
plt.gca().axes.xaxis.set_visible(False)
plt.gca().axes.yaxis.set_visible(False)
plt.title(f"Index: {idx}, Label: {label}")
plt.imshow(img, cmap='gray')

one-hot-encoding
원핫인코딩이란 간단히 말해 한개의 요소를 True로 만들고 나머지는 False로 만드는 방법이다. 주로 범주형 데이터, 문자열 데이터를 다룰 때 많이 사용한다.
애초에 y값이 문자열이 아니기 때문에 굳이 원핫인코딩을 할 필요가 없다. 대신 모델을 학습할 때, loss function을 categorical_crossentropy가 아닌 sparse_categorical_crossentropy로 설정해야 한다.
언젠간 쓸 일이 있을수도 있으니 원핫인코딩을 해보겠다.
원핫인코딩을 하기 전에 y_train[0]의 값은 5이다. 원핫벡터로 인코딩을 하면 10개의 배열안에 5에 해당하는 인덱스만 1로 설정된 것을 볼 수 있다.
print(f"기본형태: {y_train[0]}")
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
print(f"원핫인코딩 형태: {y_train[0]}")
기본형태: 5
원핫인코딩 형태: [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
모델생성
데이터 처리 부분이 끝났으면 모델을 생성하자.
Convolution Layer는 (5, 5)짜리 필터 32개를 생성하였고 활성화 함수로는 relu를 사용하였다.
input으로는 아까 차원을 늘려준 (28, 28, 1)이 들어간다.
Pooling Layer는 Maxpooling을 사용하였고 (2, 2)인 정사각형이다.
Flatten은 다차원 데이터를 1차원으로 만들어준다.
Dense Layer의 unit수는 128로 만들어 주었다. Dense Layer는 Fully conneted Layer라고도 하는데, Flatten의 output으로 나온 4608의 노드가 각각 128 unit으로 들어간다.
마지막 Dense Layer의 unit은 10으로, 최종결과에 대한 결과로 나오게 된다. 여기서 10은 0~9까지 총 10개이기 때문이고, 활성화 함수인 softmax는 10개의 출력값을 각각의 확률로 계산하게 된다.
softmax의 출력값의 합은 항상 1이다. 따라서 10개의 인덱스 중에 가장 정답일 것 같은 인덱스가 값이 제일 높다.
model = Sequential()
model.add(Conv2D(32, kernel_size=(5, 5), activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.summary()
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_7 (Conv2D) (None, 24, 24, 32) 832
max_pooling2d_5 (MaxPooling (None, 12, 12, 32) 0
2D)
flatten_5 (Flatten) (None, 4608) 0
dense_10 (Dense) (None, 128) 589952
dense_11 (Dense) (None, 10) 1290
=================================================================
Total params: 592,074
Trainable params: 592,074
Non-trainable params: 0
_________________________________________________________________
각 Layer의 파라미터수를 살펴보면 값들이 어떻게 생겨나는지 이해할 수 있다.
먼저 Conv Layer를 살펴보자. 파라미터 수는 832인데 이는 (필터 개수 * 필터 넓이 * input의 채널수 + 필터 개수)공식을 사용하면 (32 * 25 * 1 + 32)이므로 832가 된다.
Pooling Layer는 단순히 축소시키는 작업을 하므로 파라미터수의 변화가 없다.
Dense Layer의 공식은 (input_shape * output_shape - output_shape)이다. 이 공식을 사용하면 (4608 * 128 + 128)이므로 589952가 나온다. 첫번째 Dense Layer의 input은 Flatten을 거친 4608이라는 것에 주의하자. 두번째 Dense Layer도 (128 * 10 + 10)이므로 1290이 된다.
여기서 왜 Dense Layer가 Fully connected Layer라고 불리는지 알것이다. 파라미터 수를 보면 Flatten에서 나온 노드 개수가 Dense Layer의 unit에 모두 연결된다.
모델 학습
모델을 만들었으면 학습을 진행하자. loss function으로는 원핫인코딩을 했기 때문에 categorical_crossentropy를 사용하고 옵티마이저는 SGD말고 그냥 adam을 사용했다. metrics는 학습중에 확인할 척도를 정하는 것인데 정확도를 알고 싶으므로 accuracy를 사용하였다.
fit() 메서드에 validation_data부분에 테스트 데이터를 넣어주면 학습중에 테스트 데이터에 대한 손실과 정확도를 확인할 수 있다. 또한 fit()메서드를 변수에 할당하면 각 에폭의 결과가 딕셔너리 형태로 저장된다.
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(x_train, y_train, batch_size=128, epochs=10, verbose=1, validation_data=(x_test, y_test))
Epoch 1/10
469/469 [==============================] - 5s 9ms/step - loss: 0.2089 - accuracy: 0.9394 - val_loss: 0.0653 - val_accuracy: 0.9792
Epoch 2/10
469/469 [==============================] - 4s 9ms/step - loss: 0.0618 - accuracy: 0.9813 - val_loss: 0.0454 - val_accuracy: 0.9840
Epoch 3/10
469/469 [==============================] - 4s 9ms/step - loss: 0.0429 - accuracy: 0.9873 - val_loss: 0.0415 - val_accuracy: 0.9855
Epoch 4/10
469/469 [==============================] - 4s 9ms/step - loss: 0.0316 - accuracy: 0.9901 - val_loss: 0.0356 - val_accuracy: 0.9878
Epoch 5/10
469/469 [==============================] - 4s 9ms/step - loss: 0.0235 - accuracy: 0.9931 - val_loss: 0.0336 - val_accuracy: 0.9886
Epoch 6/10
469/469 [==============================] - 4s 9ms/step - loss: 0.0172 - accuracy: 0.9948 - val_loss: 0.0328 - val_accuracy: 0.9880
Epoch 7/10
469/469 [==============================] - 4s 9ms/step - loss: 0.0144 - accuracy: 0.9955 - val_loss: 0.0346 - val_accuracy: 0.9892
Epoch 8/10
469/469 [==============================] - 4s 9ms/step - loss: 0.0105 - accuracy: 0.9968 - val_loss: 0.0384 - val_accuracy: 0.9885
Epoch 9/10
469/469 [==============================] - 4s 9ms/step - loss: 0.0103 - accuracy: 0.9969 - val_loss: 0.0397 - val_accuracy: 0.9886
Epoch 10/10
469/469 [==============================] - 4s 9ms/step - loss: 0.0061 - accuracy: 0.9982 - val_loss: 0.0398 - val_accuracy: 0.9888
모델 평가
학습이 끝났으면 evaluate()으로 모델의 성능을 평가 할 수 있다. 훈련데이터로도 평가를 할 수 있지만, 우리는 테스트 성능이 궁금하기 때문에 테스트 데이터를 넣어본다.
loss는 약 0.04, 정확도는 약 0.99가 나왔다. 아주 좋은 모델이다..
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
Test loss: 0.04065585136413574
Test accuracy: 0.9897000193595886
훈련 시각화
변수에 할당된 딕셔너리 값으로 훈련 과정을 시각화 할 수도 있다.
loss = history.history["loss"]
acc = history.history["accuracy"]
val_loss = history.history["val_loss"]
val_acc = history.history["val_accuracy"]
plt.figure(figsize=(15, 5))
plt.subplot(1,2,1)
plt.plot(loss,label = "Train Loss")
plt.plot(val_loss,label = "Validation Loss")
plt.grid()
plt.legend()
plt.subplot(1,2,2)
plt.plot(acc,label = "Train Accuracy")
plt.plot(val_acc,label = "Validation Accuracy")
plt.grid()
plt.legend()
plt.show()
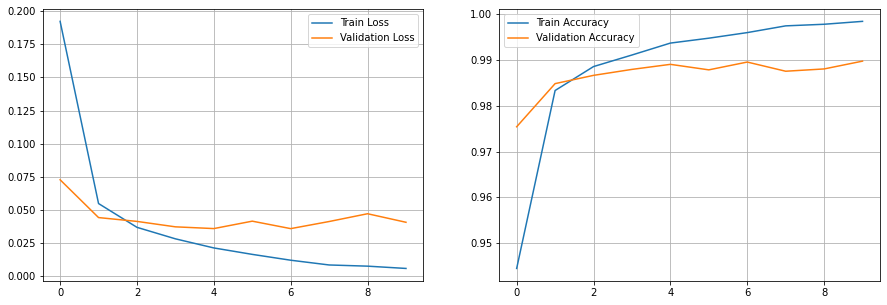
예측
모델이 훈련되었다면 이 모델이 쓸만한지 예측하는 작업이 필요하다. 모델의 예측은 predict()메서드로 가능하며 테스트 데이터에 대해 예측을 수행한다.
테스트 데이터의 shape이 (10000, 10)이므로 모든 테스트 데이터에 대해 예측을 수행한 것이다.
pred = model.predict(x_test)
print(pred.shape)
313/313 [==============================] - 1s 2ms/step
(10000, 10)
이제 예측 결과를 한번 보자. 0번째 인덱스를 출력해보니 10개의 배열이 나왔다.
이게 뭘 의미하는 것일까? 아까 위에 말한대로 출력층의 softmax 활성화 함수는 확률로 따져본다고 했다. 이 10개 중에 가장 정답일 확률이 높은 인덱스의 값이 제일 높을 것이다.
값이 가장 높은 인덱스는 numpy의 argmax()메서드를 통해서 확인 할 수 있다. 이 메서드는 각 인덱스중에서 가장 값이 높은 인덱스를 반환한다.
예측한 값은 7이고 실제 값을 확인해보니 7로 나왔다. 이로써 예측 결과의 0번째 인덱스는 잘 분류하였다.
print(f"확률 결과: {pred[0]}")
print(f"값이 가장 큰 인덱스: {np.argmax(pred[0])}")
print(f"실제 y값: {np.argmax(y_test[0])}")
확률 결과: [5.53341158e-11 4.75841766e-09 5.39768656e-08 1.27244869e-06
2.03130776e-11 1.01760454e-10 3.62447897e-15 9.99998510e-01
1.04027953e-09 1.63198393e-07]
값이 가장 큰 인덱스: 7
실제 y값: 7
예측 이미지
테스트 데이터의 이미지를 시각화 하자.
각 이미지의 제목으로 정답과 예측 결과를 출력했는데 정말 잘 맞춘다. 하긴 정확도가 99%니까..
random_index = np.random.randint(len(x_test), size=5)
plt.figure(figsize=(15, 15))
for i, idx in enumerate(random_index):
img = x_test[idx]
predict = np.argmax(pred[idx])
true = np.argmax(y_test[idx])
plt.subplot(1, len(random_index), i+1)
plt.gca().axes.xaxis.set_visible(False)
plt.gca().axes.yaxis.set_visible(False)
plt.title(f"true: {true}, predict: {predict}")
plt.imshow(img, cmap='gray')
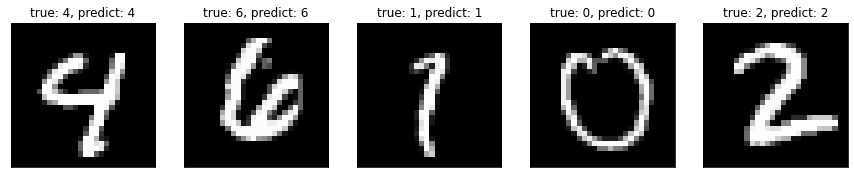
예측 실패 이미지
총 틀린 갯수는 10000개중 112개이며 틀린 인덱스를 추출해서 이미지와, 정답, 예측 결과를 시각화 해보자
wrong_index_list=[]
for index in range(10000):
if np.argmax(y_test[index]) != np.argmax(pred[index]):
wrong_index_list.append(index)
print("총 틀린 갯수 : ",len(wrong_index_list))
총 틀린 갯수 : 112
random_index = np.random.choice(wrong_index_list, 5)
plt.figure(figsize=(15, 15))
for i, idx in enumerate(random_index):
img = x_test[idx]
predict = np.argmax(pred[idx])
true = np.argmax(y_test[idx])
plt.subplot(1, len(random_index), i+1)
plt.gca().axes.xaxis.set_visible(False)
plt.gca().axes.yaxis.set_visible(False)
plt.title(f"true: {true}, predict: {predict}")
plt.imshow(img, cmap='gray')
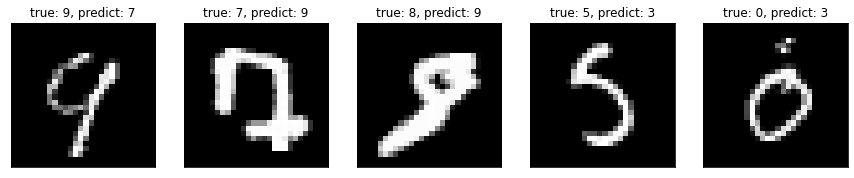
사람이 보면 그래도 대충은 알겠는데, 기계가 예측하기에는 너무 힘든가보다….
이로써 CNN을 이용한 Mnist데이터셋 분류를 마치겠다!!
댓글남기기