
자연어처리-3 seq2seq(시퀀스투시퀀스)모델에 대하여
seq2seq(Sequence-to-Sequence)란?
seq2seq는 입력된 시퀀스로부터 다른 시퀀스를 출력하는 모델이다.
입력 시퀀스에 질문, 출력 시퀀스에 답변으로 구성하면 챗봇을 만들 수 있고, 입력 시퀀스에 문장과 출력 시퀀스에 번역문장으로 구성하면 번역기를 만들 수 있다.
꼭 언어쪽에서 사용하는 모델이 아니라 이미지, 영상등 데이터가 시퀀스로 이루어져 있으면 사용이 가능하다!
모델은 대략적으로 이렇게 동작한다.

만약 시퀀스가 문장이라면 각각의 아이템은 토근을 나타내고, 동영상이라면 프레임별 이미지를 나타낼 것이다. 입력 데이터와 출력데이터의 크기가 같을 필요는 없다.
seq2seq모델은 대표적으로 기계번역에 사용되기 때문에 지금부터 번역task에 중점을 두고 설명하겠다.

위 그림은 3개의 단어로 이루어진 프랑스어 문장이 모델을 거쳐 4개의 단어로 이루어진 영어 문장으로 번역하는 과정을 나타낸 것이다. 그렇다면 가운데에 있는 모델은 어떻게 생겼을까?
Encoder-Decoder
seq2seq모델은 인코더와 디코더가 연결된 구조로 이루어져 있다.
인코더는 입력 데이터를 어떻게 압축할 것인지 담당하고, 디코더는 압축된 데이터를 어떤식으로 반환할지를 담당한다.
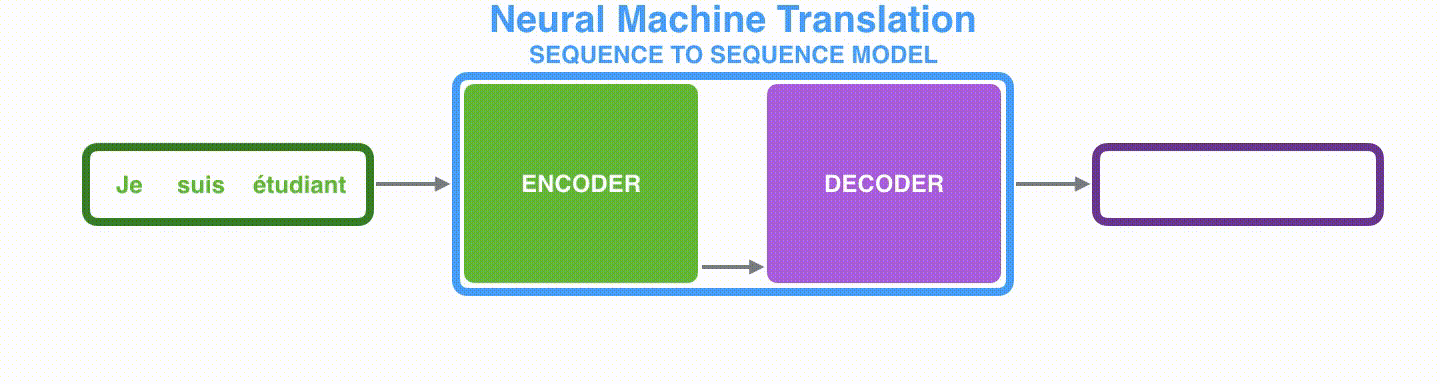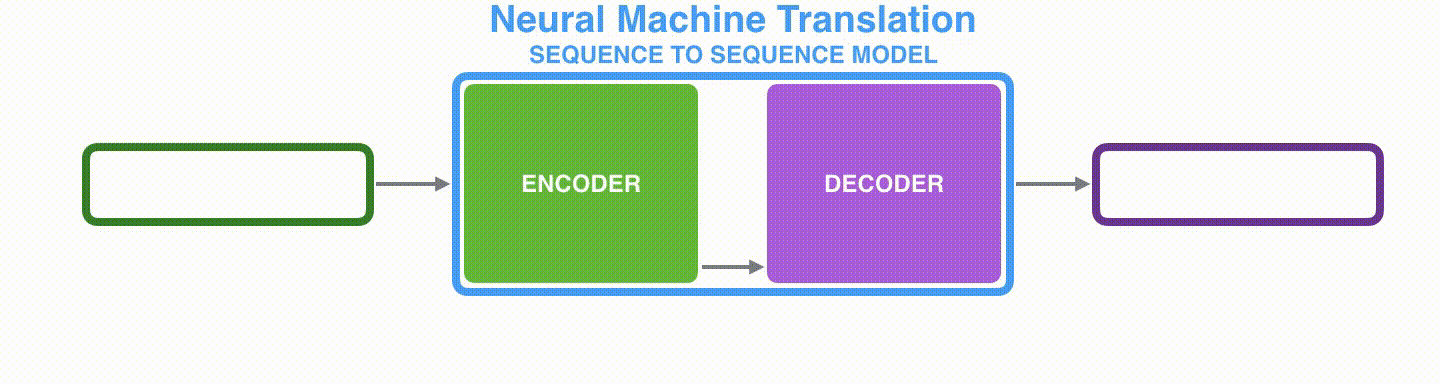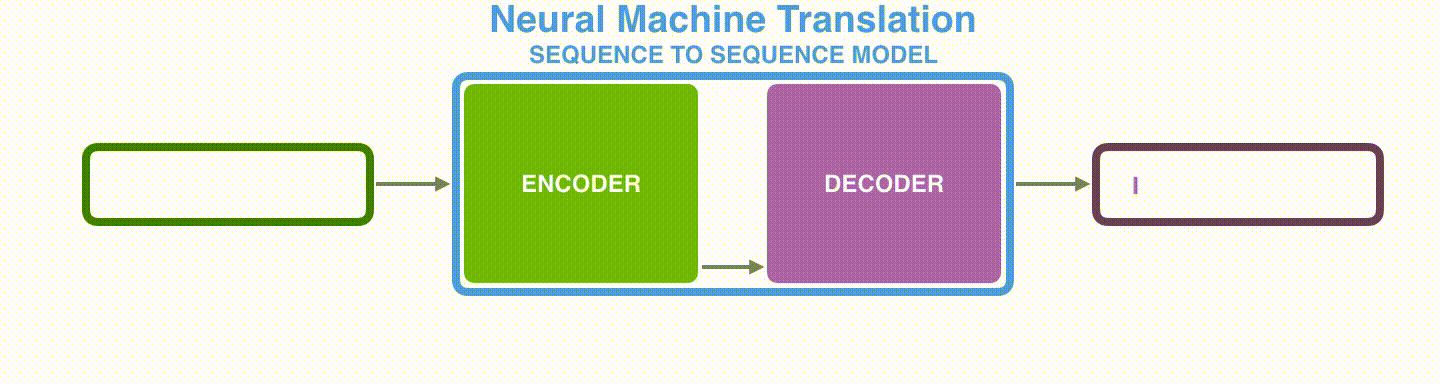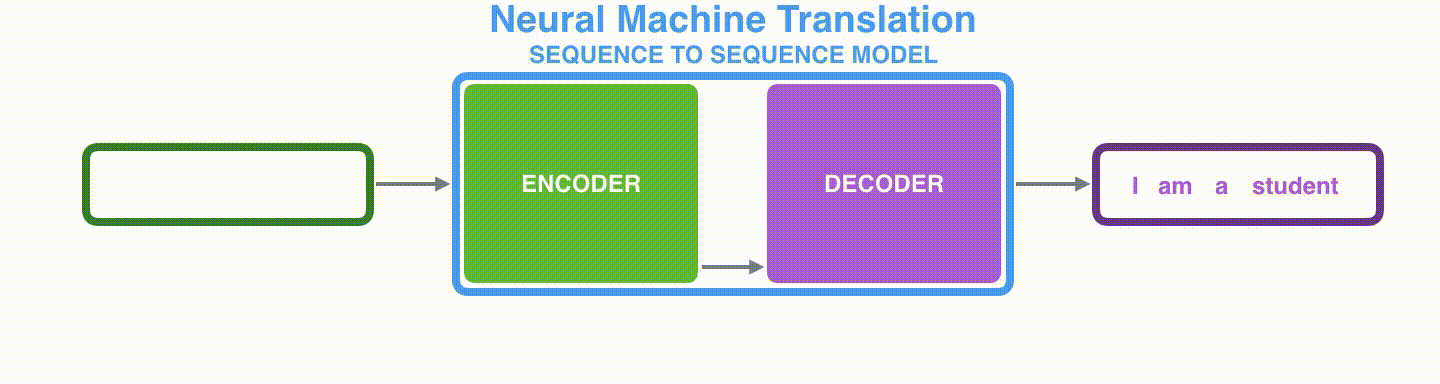
입력 시퀀스는 인코더로 들어간다. 그리고 인코더는 들어온 데이터를 압축하여 하나의 벡터를 만든다. 그것을 문맥(Context)벡터라고 한다. 인코더로부터 만들어진 컨텍스트 벡터를 디코더에게 넘겨준다. 디코더는 이를 받아 새로운 시퀀스를 출력하게 된다.
인코더와 디코더 부분을 자세하게 살펴보자. 인코더와 디코더의 내부는 사실 RNN 구조로 이루어져 있다. 실제로는 성능문제로 인해 바닐라 RNN이 아닌 LSTM이나 GRU로 구성된다. RNN에 관해서는 자연어처리 포스팅에서 많이 설명했으니 참고하기 바란다.
각 단계별로 번역을 어떻게 수행하는지 알아보자. 우선 첫 번째 단어가 인코더의 RNN으로 들어간다. 그리고 hidden state값을 내보낸다. 인코더의 두 번째 RNN은 첫 번째 RNN에서 나온 hidden state와 두 번째 입력 단어와 함께 두번째 hidden state를 내보낸다. 이렇게 해서 마지막 RNN은 최종 hidden state를 output으로 내보내는데 이것이 컨텍스트 벡터이다.
컨텍스트 벡터는 길이가 긴 시퀀스가 입력으로 들어왔을 때, 제한된 크기로 압축해야 되기 때문에 데이터의 손실이 발생한다. 이것이 seq2seq모델의 단점이다. 나중에 포스팅 하겠지만 attention 메커니즘을 통해 이 단점을 해결한다.
디코더 부분을 자세히 살펴보자.
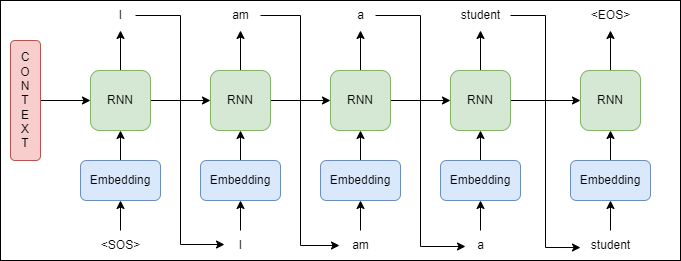
seq2seq의 훈련방식은 인코더가 보낸 컨텍스트 벡터와 실제 정답인 SOS I am a student를 입력받았을 때, I am a student EOS가 나오도록 학습한다. 테스트 과정에서는 훈련된 인코더에 시퀀스를 넣고 반환된 컨텍스트 벡터와 디코더의 SOS 토큰만 입력받은 후에 다음에 올 단어를 예측하고 최종적으로 EOS 토큰이 예측으로 나왔을 때, 테스트 과정을 종료하는 과정으로 시행된다.
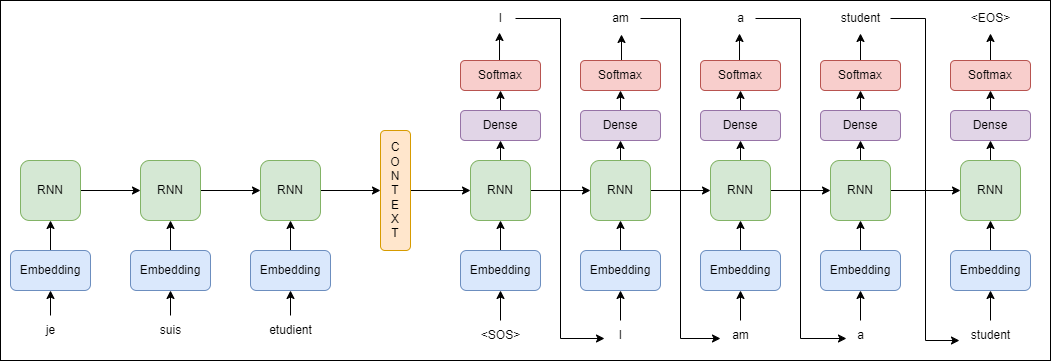
seq2seq의 최종 구조이다. 컨텍스트 벡터를 기준으로 왼쪽이 인코더, 오른쪽이 디코더 부분이다. 디코더 부분에서 최종 출력단에는 Softmax로 나올 수 있는 단어들의 확률이 젤 높은 부분을 출력하게 된다.
지금까지 가장 기본적인 seq2seq 모델에 대해서 알아보았다. 컨텍스트 벡터를 디코더의 초기 은닉 상태로만 사용할 수도 있고, 디코더의 매 시점마다 하나의 입력으로 사용할 수도 있다. 따라서 복잡한 구조도 만들 수 있다. 다음 시간에는 seq2seq 실습과 어텐션 매커니즘에 대해서 알아보겠다.
댓글남기기