
seq2seq모델에 어텐션 매커니즘을 추가해보자
어텐션을 적용한 seq2seq
지난시간 seq2seq에 이어 이번 포스팅에서는 어텐션 매커니즘을 추가한 seq2seq를 만들어보겠다.
seq2seq 포스팅은 여기, 어텐션 매커니즘 포스팅은 여기를 참고하면된다.
데이터 불러오기 및 전처리는 seq2seq포스팅과 같기때문에 모델생성 부분부터 시작하겠다.
import tensorflow as tf
from tensorflow.keras.layers import Embedding, Masking, LSTM, Dense, Input, Attention
from tensorflow.keras.models import Model
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.preprocessing.text import Tokenizer
import unicodedata
import numpy as np
import pandas as pd
import re
import os
os.environ["CUDA_VISIBLE_DEVICES"]="2"
훈련 Encoder
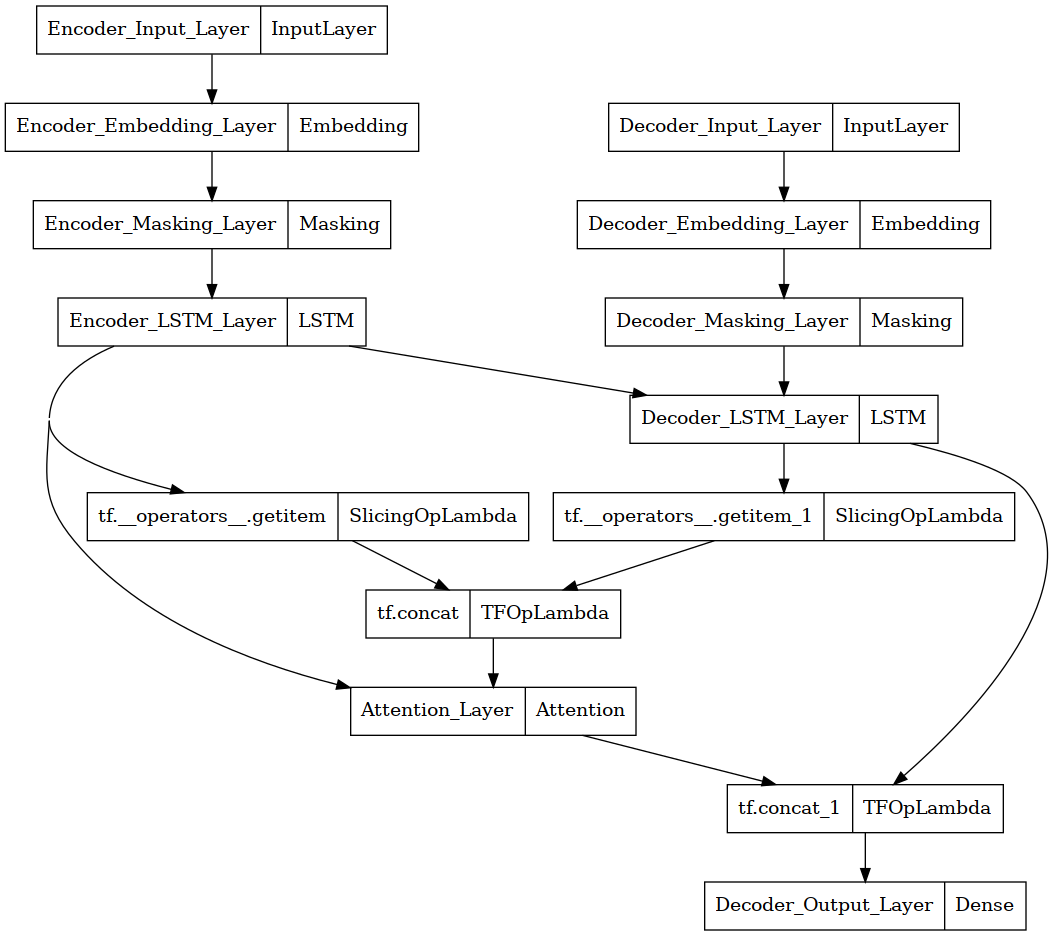
encoder_inputs = Input(shape=(None,), name="Encoder_Input_Layer")
enc_emb = Embedding(src_vocab_size, 64, name="Encoder_Embedding_Layer")(encoder_inputs)
enc_masking = Masking(mask_value=0.0, name="Encoder_Masking_Layer")(enc_emb)
encoder_lstm = LSTM(64, return_state=True, name="Encoder_LSTM_Layer")
encoder_outputs, state_h, state_c = encoder_lstm(enc_masking)
encoder_states = [state_h, state_c]
훈련 Encoder는 seq2seq의 Encoder모델과 동일하다.
훈련 Decoder
decoder_inputs = Input(shape=(None,), name="Decoder_Input_Layer")
dec_emb = Embedding(tar_vocab_size, 64, name="Decoder_Embedding_Layer")(decoder_inputs)
dec_masking = Masking(mask_value=0.0, name="Decoder_Masking_Layer")(dec_emb)
decoder_lstm = LSTM(64, return_sequences=True, return_state=True, name="Decoder_LSTM_Layer")
decoder_outputs, _, _ = decoder_lstm(dec_masking, initial_state=encoder_states)
# 어텐션적용
S_ = tf.concat([state_h[:, tf.newaxis, :], decoder_outputs[:, :-1, :]], axis=1)
attention = Attention(name="Attention_Layer")
context_vector = attention([S_, state_h])
concat = tf.concat([decoder_outputs, context_vector], axis=-1)
decoder_dense = Dense(tar_vocab_size, activation='softmax', name="Decoder_Output_Layer")
decoder_outputs = decoder_dense(concat)
여기서 지난 seq2seq와는 다르게 어텐션을 적용하는 코드가 추가되었다. 자세히 한번 보자.
S_ = tf.concat([state_h[:, tf.newaxis, :], decoder_outputs[:, :-1, :]], axis=1) 이 코드는 디코더의 마지막 시점, 즉 마지막 hidden state를 제외한 모든 시점과 인코더의 hidden state와 concat한다. 인코더의 은닉상태 형태는 (None, 64)이므로 decoder_outputs와 형태를 맞춰주기 위해서 축을 추가하였다.
attention = Attention(name="Attention_Layer")
context_vector = attention([S_, state_h])
그 다음 attention Layer에, concat한 값과 인코더의 마지막 은닉상태를 넣어준다.
concat = tf.concat([decoder_outputs, context_vector], axis=-1)
decoder_dense = Dense(tar_vocab_size, activation='softmax', name="Decoder_Output_Layer")
decoder_outputs = decoder_dense(concat)
이 코드에서는 decoder_outputs와 context_vector를 concat하여 최종 출력단으로 넘겨준다.
학습 모델 생성
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
모델 시작화
from tensorflow.keras.utils import plot_model
plot_model(model)
모델 체크포인트 지정
ckpt_path = checkpoint_path = "./training_1/cp.ckpt"
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=ckpt_path,
save_weights_only=True,
verbose=1)
모델훈련
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['acc'])
model.fit(x=[encoder_input_train, decoder_input_train], y=decoder_target_train,
validation_data=([encoder_input_test, decoder_input_test], decoder_target_test),
batch_size=128, epochs=50, callbacks = [cp_callback])
Epoch 50/50
1142/1143 [============================>.] - ETA: 0s - loss: 0.1830 - acc: 0.9566
Epoch 50: saving model to ./training_1/cp.ckpt
1143/1143 [==============================] - 79s 69ms/step - loss: 0.1830 - acc: 0.9566 - val_loss: 0.3560 - val_acc: 0.9379
<keras.callbacks.History at 0x7f5b4fef1910>
A100기준 약 1시간정도 소요
추론 Encoder
encoder_model = Model(encoder_inputs, encoder_states)
추론 Decoder
decoder_state_input_h = Input(shape=(64,))
decoder_state_input_c = Input(shape=(64,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
encoder_state_h = Input(shape=(64, ))
decoder_outputs, d_state_h, d_state_c = decoder_lstm(dec_emb, initial_state=decoder_states_inputs)
decoder_states2 = [d_state_h, d_state_c]
# 어텐션 적용
S_ = tf.concat([encoder_state_h[:, tf.newaxis, :], decoder_outputs[:, :-1, :]], axis=1)
context_vector = attention([S_, encoder_state_h])
decoder_concat = tf.concat([decoder_outputs, context_vector], axis=-1)
decoder_outputs = decoder_dense(decoder_concat)
encoder_state_h 이 코드는 인코더의 마지막 은닉상태를 담는 변수이다.
추론 모델 생성
decoder_model = Model([decoder_inputs, encoder_state_h] + decoder_states_inputs, [decoder_outputs] + decoder_states2)
추론
def decode_sequence(input_seq):
# encoder의 state_value(state_h, state_c)를 저장
states_value = encoder_model.predict(input_seq)
# encoder의 state_value중 state_h를 저장
e_state = states_value[0]
# <SOS>에 해당하는 정수 생성
target_seq = np.zeros((1,1))
target_seq[0, 0] = tar_to_index['<sos>']
stop_condition = False
decoded_sentence = ''
# stop_condition이 True가 될 때까지 루프 반복
while not stop_condition:
# target_seq와 encoder의 state_h를 넣고, state_value를 디코더의 input으로 전달. 여기서 e_state는 변하지 않음
output_tokens, h, c = decoder_model.predict([target_seq, e_state] + states_value)
# 예측 결과를 단어로 변환
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_char = index_to_tar[sampled_token_index]
# 현재 시점의 예측 단어를 예측 문장에 추가
decoded_sentence += ' '+sampled_char
# <eos>에 도달하거나 정해진 길이를 넘으면 중단.
if (sampled_char == '<eos>' or
len(decoded_sentence) > 50):
stop_condition = True
# 현재 시점의 예측 시퀀스를 다음 시점의 입력으로 사용하기 위해 저장
target_seq = np.zeros((1,1))
target_seq[0, 0] = sampled_token_index
# 현재 시점의 상태를 다음 시점의 상태로 사용하기 위해 저장
states_value = [h, c]
return decoded_sentence
def seq_to_src(input_seq):
sentence = ''
for encoded_word in input_seq:
if(encoded_word != 0):
sentence = sentence + index_to_src[encoded_word] + ' '
return sentence
# 번역문의 정수 시퀀스를 텍스트 시퀀스로 변환
def seq_to_tar(input_seq):
sentence = ''
for encoded_word in input_seq:
if(encoded_word != 0 and encoded_word != tar_to_index['<sos>'] and encoded_word != tar_to_index['<eos>']):
sentence = sentence + index_to_tar[encoded_word] + ' '
return sentence
for seq_index in [0, 1, 2, 3, 4]:
input_seq = encoder_input_test[seq_index: seq_index + 1]
decoded_sentence = decode_sequence(input_seq)
print("입력문장 :",seq_to_src(encoder_input_test[seq_index]))
print("정답문장 :",seq_to_tar(decoder_input_test[seq_index]))
print("번역문장 :",decoded_sentence[1:-5])
print("-"*50)
입력문장 : they kissed in the rain .
정답문장 : ils se sont embrasses sous la pluie .
번역문장 : ils se sont dirigees vers la foule .
--------------------------------------------------
입력문장 : you're the oldest .
정답문장 : c'est vous le doyen .
번역문장 : tu es le doyen .
--------------------------------------------------
입력문장 : do you know how to pronounce this word ?
정답문장 : connaissez vous la maniere de prononcer ce mot ?
번역문장 : savez vous ce que j'eteigne la patronne ?
--------------------------------------------------
입력문장 : i thank you for that .
정답문장 : je vous en remercie .
번역문장 : je vous remercie de tout ca .
--------------------------------------------------
입력문장 : what is that sound ?
정답문장 : c est quoi , ce bruit ?
번역문장 : qu'est ce qui vous a triche ?
--------------------------------------------------
오늘의 정리
seq2seq에 attention을 적용해보았는데, Attention matrix를 출력하지 못하니까 attention이 제대로 되었는지 의문이다… 다음에는 더 공부해서 Attention matrix까지 출력을 해보아야 겠다.
댓글남기기