
자연어처리-5 Transformer(1)
정말 오랜만에 다시 글을 쓰러 왔다. 지금까지는 학부생이었는데, 지금은 직장인이 되었다..
오늘은 Transformer에 대해서 알아보려고 한다. 공부하는데 어려움이 있었지만 꽤 흥미로웠다!!
본 포스팅은 2편으로 만들 예정이고, 1편에서는 간단한 구조를 알아보고 2편에서는 코드를 통해 구현해보겠다.
트랜스포머란 무엇인가?
- 딥러닝 기반의 인공 신경망 모델로, 주로 NLP 작업에 활용되는 혁신적인 아키텍처
- 온전히 Attention 매커니즘을 기반으로 함
- 긴 문장이나 문서에 대한 효과적인 처리가 가능하기 때문에, 번역, 요약, 생성 등 다양한 작업에 활용
- 효율적인 병렬처리와 확장성이 용이하며, 장기 의존성을 효과적으로 학습할 수 있음
- 이미지 및 음성 처리와 같은 멀티모달 작업에도 널리 활용
간략하게 5개로 설명해 보았다. 기존의 RNN, LSTM, seq2seq의 단점을 거의 보완한 완전체 아키텍처라고 할 수 있다.
기존 모델에서는 불가능 했던 장기 의존성 문제를 해결하고, 효율적인 병렬처리로 인한 높은 확장성을 가진다.
또한 요즘 나오는 GPT4같이 음성, 이미지 등등 멀티 모달로도 많이 사용한다.
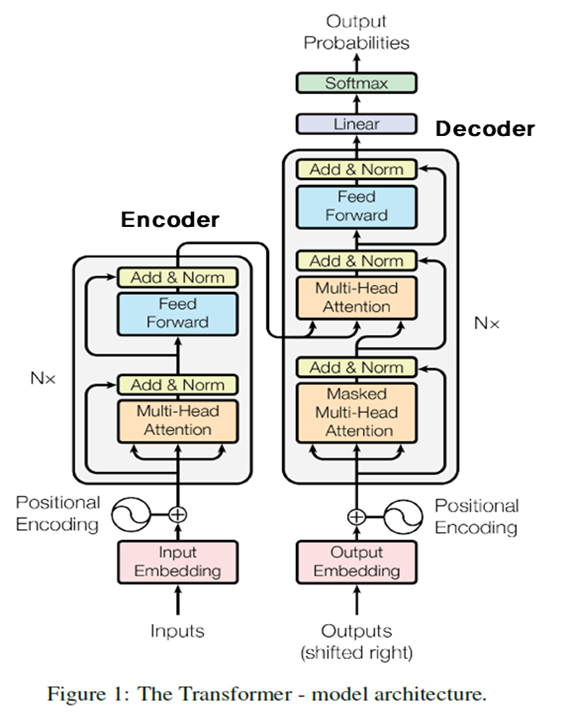
구조를 살펴보면 위 사진과 같다. 여기서는 일단 크게 인코더와 디코더로 나누어져 있다고만 알아두자.
Attention mechanism
어텐션 매커니즘이란 입력 문장의 모든 단어를 동일한 가중치로 취급하지 않고, 출력에서 특정 위치에 대응하는 단어에 더 많은 가중치를 부여하는
일종의 알고리즘? 이다. 문장 번역을 예로 들어보면, 입력에는 ‘I am a student’의 문장이 들어오고, ‘나는 학생 입니다.’라는 문장이 출력으로 나갈 때,
‘나는’이라는 단어가 ‘I’, ‘am’, ‘a’, ‘student’의 단어중 어느 것과 더 연관이 있는지를 인식하고 ‘I’라는 단어에 더 많은 가중치를 부여한다고 생각하면 된다.
자세한 내용은 여기에 포스팅 해놓았으니 확인하면 좋다.
Self Attention
위에서 설명한 어텐션은 일반적으로 크로스 어텐션이라고 부른다. 그 이유는 어텐션의 객체가 서로 다르기 때문이다.
크로스 어텐션은 쉽게 말해 하나의 시퀀스에서 각 요소가 다른 시퀀스의 모든 요소에 대해 어텐션 연산을 수행한다. 예를들어 디코더의 특정 단어를 인코더의 모든 단어와 어텐션 연산을
수행하는 느낌이다.
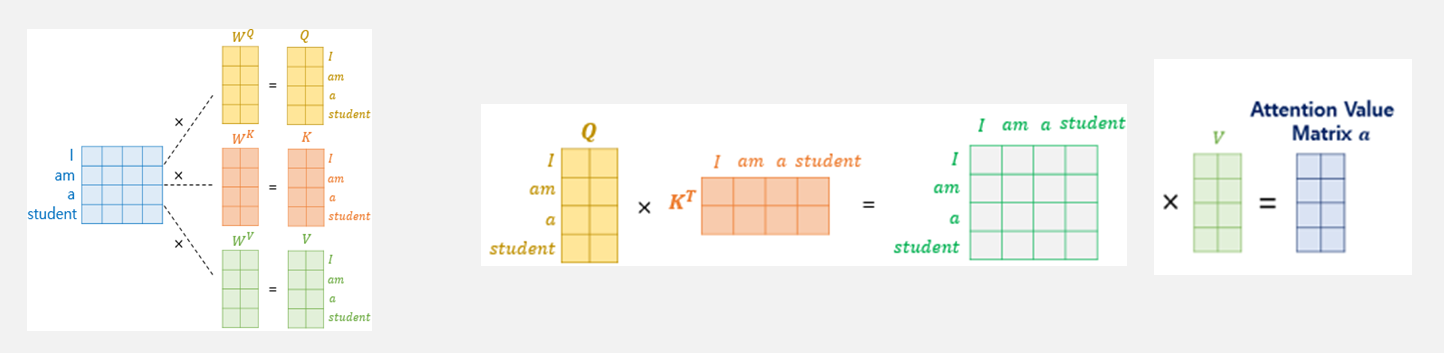
반면 셀프 어텐션은 입력 시퀀스 내에서의 어텐션을 의미한다. q, k, v의 출처는 입력 문장의 모든 단어 벡터를 의미한다.
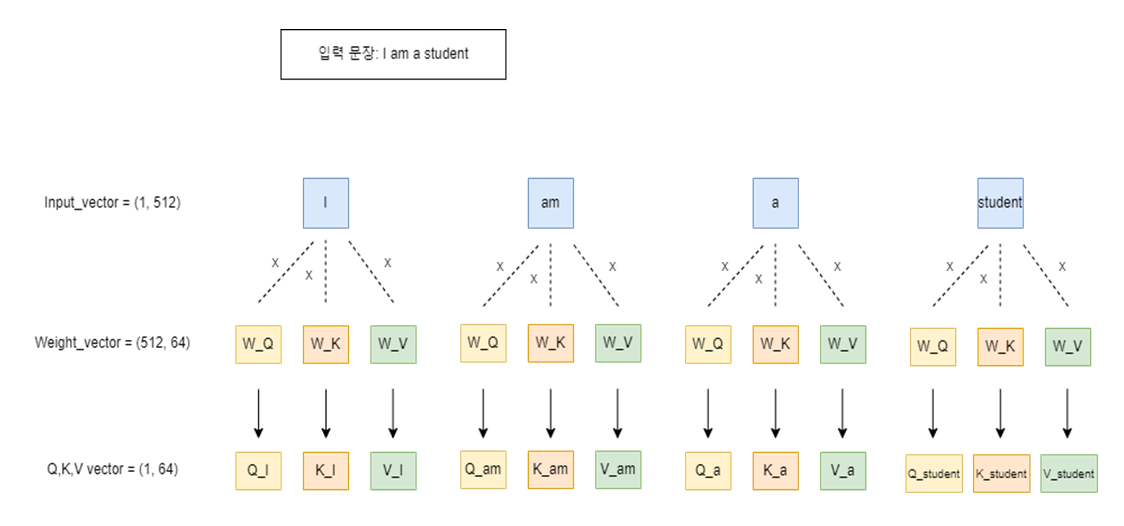
위 그림을 보면 이해가 쉽게 갈것이다. ‘I am a student’라는 입력 문장이 있을 때, 각 단어마다 가중치 행렬를 곱해서 q, k, v의 값을 구한다.
이렇게 구해진 q, k, v벡터는 각 단어마다 존재하게 된다. 그럼이제 이 q,k,v를 어떻게 할까?
아래 사진을 보자.
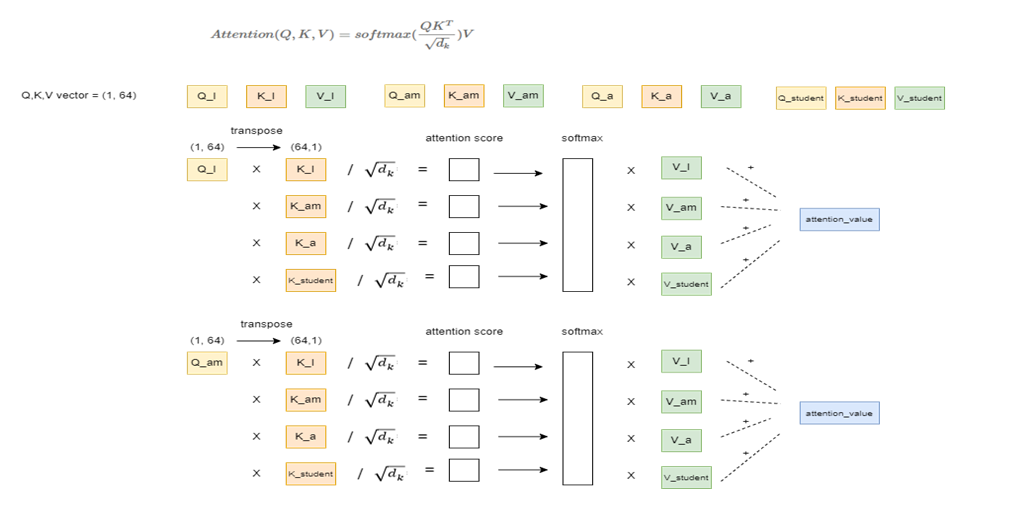
단어 ‘I’에 해당하는 q벡터를 모든 단어의 $k^T$ 벡터와 연산한다. ‘am’에 해당하는 q벡터도 모든 단어의 $k^T$ 벡터와 연산한다. 자세한 연산은 밑에서 설명하겠다.
scaled Dot-Product Attention
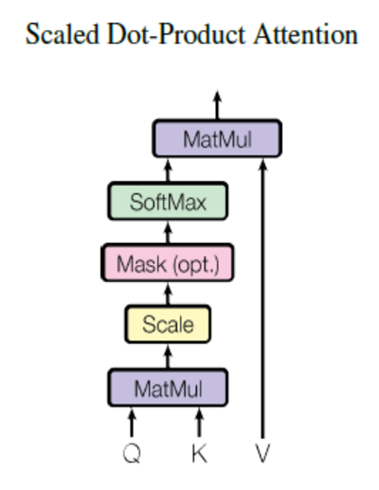
각 q벡터는 모든 $k^T$ 벡터에 대해서 attention score를 구하고, softmax를 통해 Attention distribution을 구한다. 분포를 구한 뒤 v벡터와 곱하고
값을 모두 더해서 attention value를 구한다. 일반적인 k벡터가 아니고 k를 전치시킨 벡터와 연산하는 이유는 내적하여 유사도를 구해야 하기 때문이다.
계산과정은 Attention과 다르지 않다. 하지만 앞에 Scaled가 붙은 이유는 attention score를 구하기 전에 $\sqrt{d_k}$ 로 스케일링을 해준다는 것이다.
여기서 ${d_k}$ 는 k벡터의 차원인데, 논문에서는 64를 사용하였다.
여기서 의문!! 왜 하필 $\sqrt{d_k}$ 로 스케일링 한 것일까?
그 이유는 q, k의 벡터 길이가 커질수록 벡터의 내적값 역시 커지고, softmax의 기울기가 0이 될 가능성이 높기 때문에, 평균이 0, 분산이 1인 정규분포를 따르게 하기위해서 $\sqrt{d_k}$로 스케일링을 한 것이다.
수식으로는 $Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V$ 로 나타낸다.
위의 사진들은 예시를 위한 사진이지 실제로 저렇게 낱개로 값이 계산되지는 않는다. 실제로는 행렬 단위로 연산이 수행된다.
Multi-Head Attention
아까 위에서 본 트랜스포머 구조에서 처음 나오는 멀티헤드 어텐션이다. 딱히 Attention과 다를건 없지만 병렬 Attention을 사용한 것이 특징이다.
각각의 q, k, v의 가중치 행렬은 다 다르기 때문에 여러 시점에서의 단어 연관성을 학습할 수 있다.
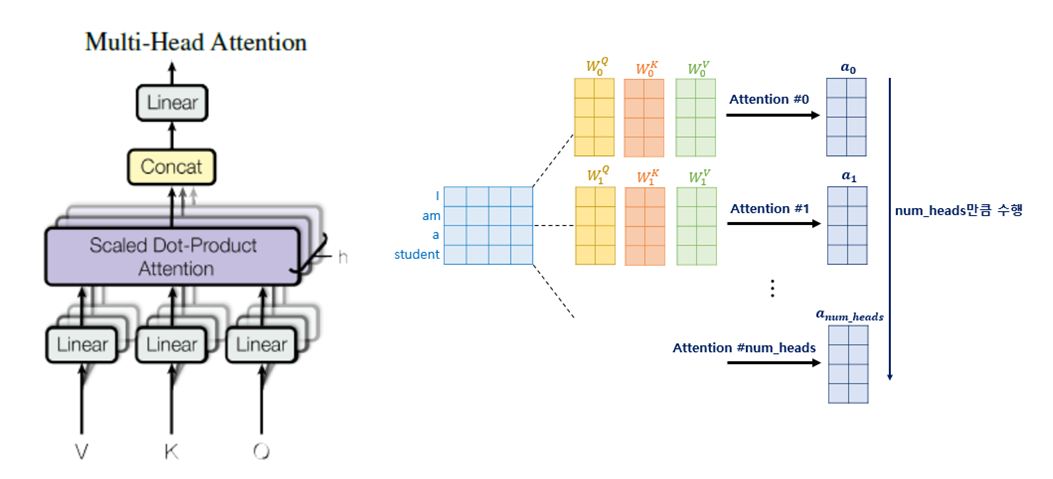
왼쪽 사진에서 Scaled Dot-Product Attention 부분이 위에서 설명한 연산이 수행되는 부분이다. 논문에서는 8개의 병렬 어텐션을 사용하여 총 8개의 attention value가 나온다.
8개의 Attention value를 concat하여 가중치 행렬 $W^O$와 곱해서 최종 출력을 낸다.
수식으로는 $MultiHead(Q, K, V) = Concat(head_1, head_2, …, head_h)W^O$ 이렇게 되겠다.
각각의 헤드를 Concat한 후 가중치 행렬 $W^O$ 를 곱하는 이유는 각 헤드에서 나온 결과를 최종 출력으로 매핑하기 위해 선형 변환을 한 것이다. 즉, 각 헤드에서 나온 정보를 최종 출력 공간으로 변환하여 모델이 학습할 수 있도록 하기 위함이다.
Positional Encoding
트랜스포머는 RNN이나 LSTM과 달리 단어를 순차적으로 입력받지 않고 한번에 입력받기 때문에 단어의 위치 정보를 가질 수 없다.
따라서 Positional Encoding을 통해 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용한다. 이렇게 하면 단어의 의미 뿐 아니라 위치 정보까지 활용이 가능해진다.
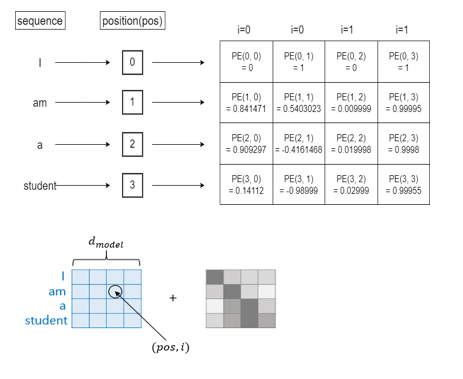
논문에서는 임베딩의 값이 너무 커지면 단어 정보가 손실된다는점, 위치정보를 표현하는 벡터들이 서로 중복되면 안된다는 점을 고려해서 sin과 cos을 이용하여 위치 임베딩을 생성한다.
이해하기 쉽게 정리하면, 값이 중복되지 않게 0, 1 사이에서 위치 임베딩을 생성한다는 것이다.
깊이 들어가면 내용이 매우 길어지기 때문에 더 자세한 정보를 알고싶으면 여기블로그를 참고하기 바란다.
Padding mask
입력 문장의 길이는 각각 다르기 때문에 길이를 맞춰 주기 위해서 ‘0’값을 넣는 패딩 작업을 진행한다.
예를 들어, 입력 문장 중 제일 긴 문장의 토큰이 10이고 가장 짧은 문장의 토큰이 3일때, 3토큰인 문장은 7개의 0으로 된 토큰을 추가하여 길이를 10으로 맞추는 것이다.
마스킹 방법은 마스킹 위치에 매우 작은 음수값(-1e9)을 곱해 어텐션 스코어 행렬에 더해준다.
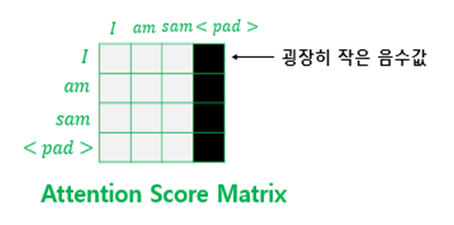
이렇게 함으로써 어텐션 스코어 행렬이 softmax를 지날 때, 마스킹 된 위치의 값들은 0에 가까운 값이 되어 유사도 계산에 영향을 주지 않는다.
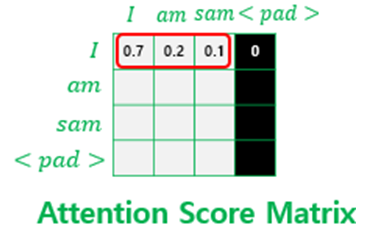
자세한 동작 과정은 2편 코드리뷰에서 설명하도록 하겠다.
Position-wise Feed Forward Neural Network
이름이 길지만 그냥 Dense Layer라고 생각하면 된다. 두개의 Dense Layer와 ReLU로 이루어져 있다.
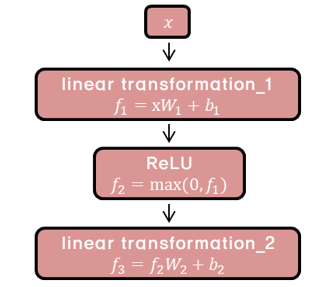
x의 값은 이전 layer의 출력을 뜻한다. 수식으로 나타내면 아래와 같다.
$FFNN(x) = MAX(0, xW_1+b_1)W_2+b_2$
Residual Connection & Layer Normalization
Residual Connection이란 서브층의 입력과 출력을 더하는 것을 의미한다. 컴퓨터 비전 분야에서 모델의 학습을 도울 때 많이 사용하는 기법인데 트랜스포머에 적용을 하였다.
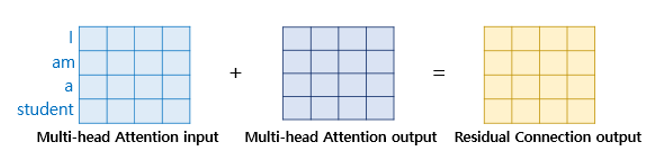 그림에서 볼수 있듯이 Multi-Head attention Layer의 input과 output을 서로 더해서 다음 layer로 보낸다.
그림에서 볼수 있듯이 Multi-Head attention Layer의 input과 output을 서로 더해서 다음 layer로 보낸다.
Layer Normalization은 일종의 정규화이다. 텐서의 마지막 차원에 대해서 평균과 분산을 0, 1로 만들어 정규분포를 따르게 한다. Gradient Vanishing, exploding 문제를 완화시킨다.
Look-ahead Mask
트랜스포머는 RNN과 다르게 문장을 한번에 입력 받으므로 현재 시점의 단어를 예측하고자 할 때, 미래 시점의 단어들 까지 참고하는 현상이 발생.
현재 시점의 예측에서 미래 시점에 있는 단어들을 참고하지 못하도록 하는 알고리즘이다.
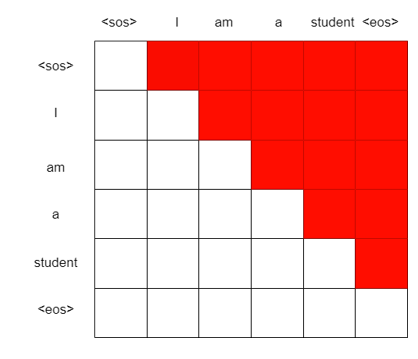
사진을 보면 SOS토큰을 예측할 때, SOS토큰만 참고하도록하고, I를 예측할때 SOS토큰과 I까지만 참고한다.
Encoder-Decoder Attention
Self-Attention과는 다르게 Cross-Attention을 하는 부분이다. 디코더의 두번 째 레이어에 해당하며, 인코더에서 넘어온 k, v를 가지고 디코더의 q와 Attention 연산을 수행한다.
댓글남기기