
자연어처리-5 Transformer(2)
오늘은 지난 트랜스포머 1편에 대한 구체적인 동작 원리를 코드를 통해 알아보도록 하겠다.
지난 포스팅이 궁금한 사람은 여기를 참고하기 바란다.
Positional Encoding
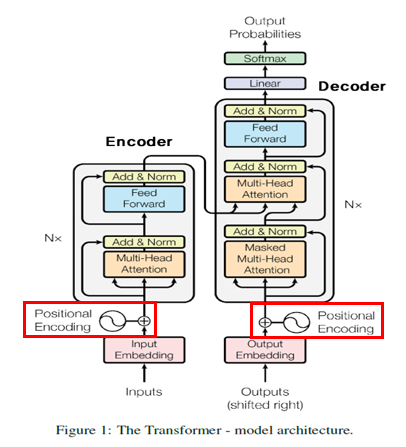
class PositionalEncoding(tf.keras.layers.Layer):
def __init__(self, position, d_model):
super(PositionalEncoding, self).__init__()
self.pos_encoding = self.positional_encoding(position, d_model)
@staticmethod
def get_angles(position, i, d_model):
angles = 1 / tf.pow(10000, (2 * (i // 2)) / tf.cast(d_model, tf.float32))
return position * angles
def positional_encoding(self, position, d_model):
angle_rads = self.get_angles(
position = tf.range(position, dtype=tf.float32)[:, tf.newaxis],
i = tf.range(d_model, dtype=tf.float32)[tf.newaxis, :],
d_model=d_model
)
sines = tf.math.sin(angle_rads[:, 0::2])
cosines = tf.math.cos(angle_rads[:, 1::2])
angle_rads = np.zeros(angle_rads.shape)
angle_rads[:, 0::2] = sines
angle_rads[:, 1::2] = cosines
pos_encoding = tf.constant(angle_rads)
pos_encoding = pos_encoding[tf.newaxis, ...]
return tf.cast(pos_encoding, tf.float32)
def call(self, inputs):
return inputs + self.pos_encoding[:, :tf.shape(inputs)[1], :]
get_angles()- position과 i, d_model를 받아서 서로 다른 값을 만들어 내는 함수이다.
- position은 입력 단어의 크기, d_model은 임베딩 벡터의 차원, i는 임베딩 벡터 차원을 range로 쭉 뽑아놓은 값이다.
positional_encoding()get_angles()함수를 통해 만들어진 값을 짝수 인덱스에는 sin을, 홀수 인덱스에는 cos을 적용하는 함수이다.- 이렇게 함으로써 포지셔널 인코딩의 값은 서로 중복되지 않는 독립적인 값을 갖게 된다.
call()- Layer 클래스에 있는 함수로, 실제 클래스가 호출될 때 실행되는 함수이다.
- inputs와 포지셔널 인코딩의 값을 더해서 반환한다. 여기서 inputs는 임베딩 벡터가 되겠다.
scaled Dot-Product Attention
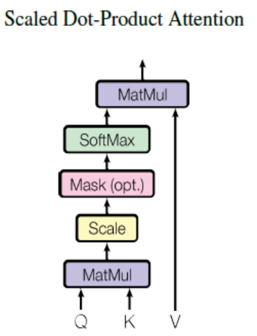
def scaled_dot_product_attention(query, key, value, mask):
# 1
matmul_qk = tf.matmul(query, key, transpose_b=True)
depth = tf.cast(tf.shape(key)[-1], tf.float32)
logits = matmul_qk / tf.math.sqrt(depth)
# 2
if mask is not None:
logits += (mask * -1e9)
# 3
attention_weights = tf.nn.softmax(logits, axis=-1)
output = tf.matmul(attention_weights, value)
return output, attention_weights
- q와 $k^T$를 곱하고 $\sqrt{d_k}$로 스케일링을 진행한다.
- 마스킹 값이 넘어오면 어텐션 행렬의 마스킹 할위치에 매우 작은 음수값을 넣는다.
- 소프트 맥스 함수를 통과한 뒤, v와 곱한다.
Padding Mast
def create_padding_mask(x):
"""
ex)
x = [0, 32, 784, 15, 0]
mask = [1, 0, 0, 0, 1]
0인곳은 1, 0이 아닌곳은 0
"""
mask = tf.cast(tf.math.equal(x, 0), tf.float32)
return mask[:, tf.newaxis, tf.newaxis, :]
- 입력 토큰이 0이면 1로 변환하고(즉 패딩은 1로 변환) 아니면 0으로 변환
- 위에
scaled_dot_product_attention()에서 패딩의 값이 1인 부분에 매우 작은 음수값을 곱하게됨
Multi-Head Attention
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, name="multi_head_attention"):
super(MultiHeadAttention, self).__init__(name=name)
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.query_dense = tf.keras.layers.Dense(units=d_model)
self.key_dense = tf.keras.layers.Dense(units=d_model)
self.value_dense = tf.keras.layers.Dense(units=d_model)
self.out_dense = tf.keras.layers.Dense(units=d_model)
# num_heads 개수만큼 q, k, v를 split하는 함수
def split_heads(self, inputs, batch_size):
inputs = tf.reshape(inputs, shape=(batch_size, -1, self.num_heads, self.depth))
return tf.transpose(inputs, perm=[0, 2, 1, 3])
def call(self, inputs):
query, key, value, mask = inputs['query'], inputs['key'], inputs['value'], inputs['mask']
batch_size = tf.shape(query)[0]
query = self.query_dense(query)
key = self.key_dense(key)
value = self.value_dense(value)
query = self.split_heads(query, batch_size)
key = self.split_heads(key, batch_size)
value = self.split_heads(value, batch_size)
# 3. 스케일드 닷 프로덕트 어텐션. 앞서 구현한 함수 사용.
scaled_attention, _ = scaled_dot_product_attention(query, key, value, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3])
# 4. 헤드 연결(concatenate)하기
concat_attention = tf.reshape(scaled_attention, (batch_size, -1, self.d_model))
# 5. WO에 해당하는 밀집층 지나기
outputs = self.out_dense(concat_attention)
return outputs
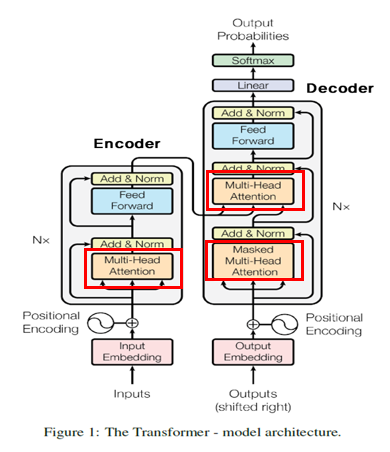
__init__()tf.keras.layers.Layer를 가져와 사용- q, k, v에 해당하는 가중치 행렬 정의
split_heads()- num_heads의 개수 만큼 q, k, v를 split하는 함수
- transpose는 차원의 순서를 바꾸는 역할을 함
call()- q, k, v가 가중치 행렬을 지남.
- q, k, v를 헤드의 개수만큼 split함
- scaled-dot-product attention 수행
- 헤드를 연결
- $W^O$ 가중치 행렬을 지나서 output을 return함
Encoder
def encoder_layer(dff, d_model, num_heads, dropout, name="encoder_layer"):
inputs = tf.keras.Input(shape=(None, d_model), name="inputs")
# 인코더는 패딩 마스크 사용
padding_mask = tf.keras.Input(shape=(1, 1, None), name="padding_mask")
# 멀티-헤드 어텐션 (첫번째 서브층 / 셀프 어텐션)
attention = MultiHeadAttention(
d_model, num_heads, name="attention")({
'query': inputs, 'key': inputs, 'value': inputs, # Q = K = V
'mask': padding_mask # 패딩 마스크 사용
})
# 드롭아웃 + 잔차 연결과 층 정규화
attention = tf.keras.layers.Dropout(rate=dropout)(attention)
attention = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(inputs + attention)
# 포지션 와이즈 피드 포워드 신경망 (두번째 서브층)
outputs = tf.keras.layers.Dense(units=dff, activation='relu')(attention)
outputs = tf.keras.layers.Dense(units=d_model)(outputs)
# 드롭아웃 + 잔차 연결과 층 정규화
outputs = tf.keras.layers.Dropout(rate=dropout)(outputs)
outputs = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention + outputs)
return tf.keras.Model(inputs=[inputs, padding_mask], outputs=outputs, name=name)
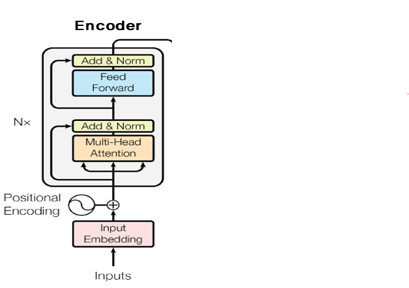 Encoder의 Multi-head attention의 q, k, v는 모두 input으로 출처가 같다.
Encoder의 Multi-head attention의 q, k, v는 모두 input으로 출처가 같다.
input과 attention을 통해 나온 값을 더하는 Residual connection을 적용하고 Normalize한다. 사진에서 Add&Norm이 이 부분이다.
그 다음 Position-wise FFNN을 통과해서 나온 output과 첫번 째 Residual connection한 값과 또 Residual connection을 해서 최종 출력 디코더로 보낸다.
def encoder(vocab_size, num_layers, dff,
d_model, num_heads, dropout,
name="encoder"):
inputs = tf.keras.Input(shape=(None,), name="inputs")
# 인코더는 패딩 마스크 사용
padding_mask = tf.keras.Input(shape=(1, 1, None), name="padding_mask")
# 포지셔널 인코딩 + 드롭아웃
embeddings = tf.keras.layers.Embedding(vocab_size, d_model)(inputs)
embeddings *= tf.math.sqrt(tf.cast(d_model, tf.float32))
embeddings = PositionalEncoding(vocab_size, d_model)(embeddings)
outputs = tf.keras.layers.Dropout(rate=dropout)(embeddings)
# 인코더를 num_layers개 쌓기
for i in range(num_layers):
outputs = encoder_layer(
dff=dff, d_model=d_model, num_heads=num_heads,
dropout=dropout, name="encoder_layer_{}".format(i))([outputs, padding_mask])
return tf.keras.Model(
inputs=[inputs, padding_mask], outputs=outputs, name=name)
위에 코드는 최종 인코더로, 위에서 구현한 encoder layer를 num_layer 개수만큼 반복하는 코드이다.
임베딩 부분과 포지셔널 인코딩 부분이 추가되어 있다.
Look-Ahead Mask
def create_look_ahead_mask(x):
seq_len = tf.shape(x)[1]
look_ahead_mask = 1 - tf.linalg.band_part(tf.ones((seq_len, seq_len)), -1, 0)
padding_mask = create_padding_mask(x) # 패딩 마스크도 포함
return tf.maximum(look_ahead_mask, padding_mask)
패딩 마스크도 포함하여 룩어헤드 마스크를 생성한다.
Decoder
def decoder_layer(dff, d_model, num_heads, dropout, name="decoder_layer"):
inputs = tf.keras.Input(shape=(None, d_model), name="inputs")
enc_outputs = tf.keras.Input(shape=(None, d_model), name="encoder_outputs")
# 룩어헤드 마스크(첫번째 서브층)
look_ahead_mask = tf.keras.Input(
shape=(1, None, None), name="look_ahead_mask")
# 패딩 마스크(두번째 서브층)
padding_mask = tf.keras.Input(shape=(1, 1, None), name='padding_mask')
# 멀티-헤드 어텐션 (첫번째 서브층 / 마스크드 셀프 어텐션)
attention1 = MultiHeadAttention(
d_model, num_heads, name="attention_1")(inputs={
'query': inputs, 'key': inputs, 'value': inputs, # Q = K = V
'mask': look_ahead_mask # 룩어헤드 마스크
})
# 잔차 연결과 층 정규화
attention1 = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention1 + inputs)
# 멀티-헤드 어텐션 (두번째 서브층 / 디코더-인코더 어텐션)
attention2 = MultiHeadAttention(
d_model, num_heads, name="attention_2")(inputs={
'query': attention1, 'key': enc_outputs, 'value': enc_outputs, # Q != K = V
'mask': padding_mask # 패딩 마스크
})
# 드롭아웃 + 잔차 연결과 층 정규화
attention2 = tf.keras.layers.Dropout(rate=dropout)(attention2)
attention2 = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention2 + attention1)
# 포지션 와이즈 피드 포워드 신경망 (세번째 서브층)
outputs = tf.keras.layers.Dense(units=dff, activation='relu')(attention2)
outputs = tf.keras.layers.Dense(units=d_model)(outputs)
# 드롭아웃 + 잔차 연결과 층 정규화
outputs = tf.keras.layers.Dropout(rate=dropout)(outputs)
outputs = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(outputs + attention2)
return tf.keras.Model(
inputs=[inputs, enc_outputs, look_ahead_mask, padding_mask],
outputs=outputs,
name=name)
인코더와 차이나는 부분만 설명하겠다.
디코더의 첫번째 어텐션은 룩어헤드 마스크를 사용한다. 또한 q, k, v의 출처가 모두 같다.
디코더의 두번째 어텐션은 패딩 마스크를 사용하고, q는 디코더에서 넘어온 값이고 k, v는 인코더의 마지막 층에서 넘어왔다는 차이가 있다.
def decoder(vocab_size, num_layers, dff,
d_model, num_heads, dropout,
name='decoder'):
inputs = tf.keras.Input(shape=(None,), name='inputs')
enc_outputs = tf.keras.Input(shape=(None, d_model), name='encoder_outputs')
# 디코더는 룩어헤드 마스크(첫번째 서브층)와 패딩 마스크(두번째 서브층) 둘 다 사용.
look_ahead_mask = tf.keras.Input(
shape=(1, None, None), name='look_ahead_mask')
padding_mask = tf.keras.Input(shape=(1, 1, None), name='padding_mask')
# 포지셔널 인코딩 + 드롭아웃
embeddings = tf.keras.layers.Embedding(vocab_size, d_model)(inputs)
embeddings *= tf.math.sqrt(tf.cast(d_model, tf.float32))
embeddings = PositionalEncoding(vocab_size, d_model)(embeddings)
outputs = tf.keras.layers.Dropout(rate=dropout)(embeddings)
# 디코더를 num_layers개 쌓기
for i in range(num_layers):
outputs = decoder_layer(dff=dff, d_model=d_model, num_heads=num_heads,
dropout=dropout, name='decoder_layer_{}'.format(i),
)(inputs=[outputs, enc_outputs, look_ahead_mask, padding_mask])
return tf.keras.Model(
inputs=[inputs, enc_outputs, look_ahead_mask, padding_mask],
outputs=outputs,
name=name)
디코더를 num_layer의 개수만큼 반복한 부분이다.
Transformer Architecture
def transformer(vocab_size, num_layers, dff,
d_model, num_heads, dropout,
name="transformer"):
# 인코더의 입력
inputs = tf.keras.Input(shape=(None,), name="inputs")
# 디코더의 입력
dec_inputs = tf.keras.Input(shape=(None,), name="dec_inputs")
# 인코더의 패딩 마스크
enc_padding_mask = tf.keras.layers.Lambda(
create_padding_mask, output_shape=(1, 1, None),
name='enc_padding_mask')(inputs)
# 디코더의 룩어헤드 마스크(첫번째 서브층)
look_ahead_mask = tf.keras.layers.Lambda(
create_look_ahead_mask, output_shape=(1, None, None),
name='look_ahead_mask')(dec_inputs)
# 디코더의 패딩 마스크(두번째 서브층)
dec_padding_mask = tf.keras.layers.Lambda(
create_padding_mask, output_shape=(1, 1, None),
name='dec_padding_mask')(inputs)
# 인코더의 출력은 enc_outputs. 디코더로 전달된다.
enc_outputs = encoder(vocab_size=vocab_size, num_layers=num_layers, dff=dff,
d_model=d_model, num_heads=num_heads, dropout=dropout,
)(inputs=[inputs, enc_padding_mask]) # 인코더의 입력은 입력 문장과 패딩 마스크
# 디코더의 출력은 dec_outputs. 출력층으로 전달된다.
dec_outputs = decoder(vocab_size=vocab_size, num_layers=num_layers, dff=dff,
d_model=d_model, num_heads=num_heads, dropout=dropout,
)(inputs=[dec_inputs, enc_outputs, look_ahead_mask, dec_padding_mask])
# 다음 단어 예측을 위한 출력층
outputs = tf.keras.layers.Dense(units=vocab_size, name="outputs")(dec_outputs)
return tf.keras.Model(inputs=[inputs, dec_inputs], outputs=outputs, name=name)
위에서 구현한 인코더와 디코더를 통합하여 만든 모델이다.
위 코드를 가지고 간단한 챗봇을 만드는 예제는 여기에 있다.
참고자료
- https://wikidocs.net/31379
댓글남기기