
로지스틱 회귀란 무엇인가?
정의
Logistic Regression는 이름에 ‘Regression’이 들어가지만 결론적으로 클래스가 2개인 이진분류를 위한 모델이다.
데이터가 어떤 범주에 속할 확률을 0에서 1사이의 확률 값으로 예측하고 그값에 따라 가능성이 더 높은 범주에 속하는 것으로 분류한다.
클래스가 2개라는 말은 (합격, 불합격), (True, False)등 결과가 두가지로 떨어지는 것을 말한다. 따라서 X는 모든 형식의 데이터를 가질 수 있지만, Y는 Binary한 데이터만을 가질 수 있다.
선형회귀와 로지스틱 회귀
선형회귀와 로지스틱회귀의 차이를 한번 보자.
</br>
</br>
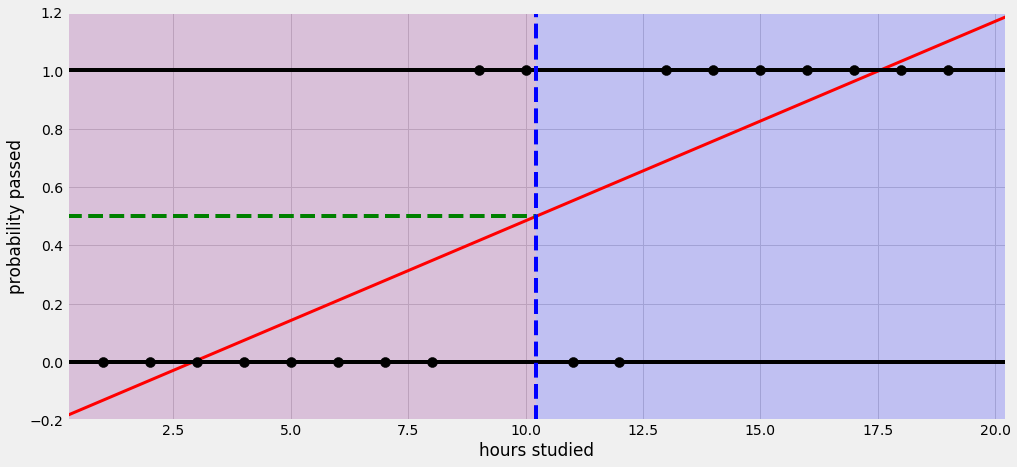
위의 사진은 일반적인 선형회귀이다. y값이 0(불합격), 1(합격)일때, 선이 $-\infin$ 부터 $+\infin$ 까지 이어진다. 이 말은 즉 확률이 0도 안되거나 100이 넘는다는 뜻이다.
이번에는 로지스틱 회귀모양을 보자
</br>
</br>
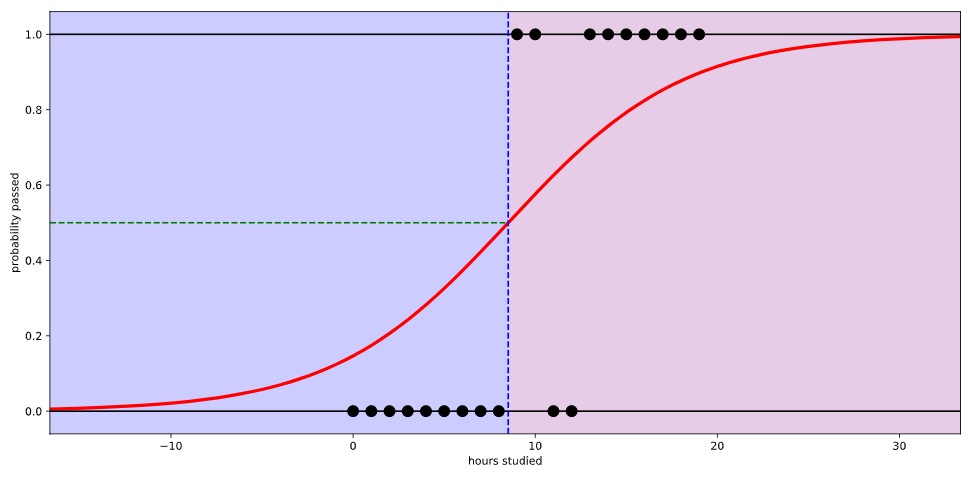
위의 사진대로 선이 곡선모양을 띄면서 확률이 0과 1 사이의 값으로 그려지는 것을 볼 수 있다. 이 곡선모양을 $sigmoid$ 함수라고 불린다.
일반 선형회귀의 식은 다 알것이다. $f(x) = wx + b$ 형태이다. 여기서 $f(x)$는 링크 함수라고 하는데 이 자리에 특별한 함수들이 들어가서 다른 회귀분석을 만들 수 있다.
다중회귀의 식은 $f(x) = w_1x_1 + w_2x_2 + … + wn_xn + b$ 형태이다.
로지스틱 회귀의 식은 일단 기본적으로 $log(p \div 1-p) = wx + b$ 형태로 생겼다.
선형회귀와 비슷한데 $f(x)$함수의 자리에 이상한 식이 들어갔다.
로지스틱 회귀분석은 선형회귀모형을 로짓으로 변형한 것이다.
Log-odds(logit)
선형 회귀에서는 각 속성값에다가 가중치를 곱하고 편향을 더해서 예측값을 구한다. 로지스틱 회귀에서도 각 속성값에 가중치를 곱하고 편향을 더하는건 같지만, 마지막에 logit값을 구해야 한다.
logit을 계산하기 위해서 먼저 odds를 알아야 한다. odds란 어떤 사건이 발생할 확률을 발생하지 않을 확률로 나눈 값이다. $P$라고 했을 때, 사건이 발생할 확률을 $P$라고 할 때, $P \div P-1$ 로 나타낸다. 이 값에 $log$를 취한 것이 logit이다. 따라서 로지스틱 회귀분석의 식은 $log(p/(1-p)) = wx + b$이다.
Sigmoid
위에서 본 로지스틱 회귀의 선은 곡선이다. 이 곡선을 만들어 주는것이 sigmoid함수이다. 수식으로는 $1 \over 1 + e^{-z}$ 로 나타낸다.
위에서 구한 logit을 sigmoid함수에 넣어서 0과 1사이의 값으로 변환시켜 준다.
Loss Function
로지스틱 회귀에서도 가중치와 편향이 적절한 값인지 확인하는 손실함수가 필요하다. 손실함수가 하는 일은 가중치와 편향의 값을 제어하면서 최적의 값을 찾는 역할을 한다.
로지스틱 회귀에서는 MSE Loss를 사용하지 않는다. 로지스틱 회귀에서는 선이 곡선 형태를 띄기 때문에 손실의 진짜 최소값이 아닌 가짜 최소값에 빠질 수도 있다.
</br>
</br>
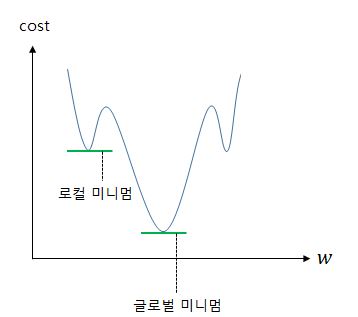
사진으로 보면 이해가 빠를것이다. 글로벌 미니멈이 진짜 최소값이고, 로컬 미니멈이 가짜 최소값이다. 따라서 새로운 손실함수가 필요하다.
샘플 데이터의 개수가 $n$개 이고, 어떤함수 $f(x)$가 실제값 $y^i$와 예측값 $H(x_i)$의 오차를 나타내는 함수를 $J(w) = \frac{1}{n} \sum_{i=1}^{n} f\left(H(x^{(i)}), y^{(i)}\right)$ 라고 해보자. 여기서 $f$ 를 어떻게 정의하느냐에 따라서 적절한 손실함수가 완성된다. 그럼 로지스틱 회귀의 손실함수를 만들어보자.
sigmoid함수는 0~1 사이의 값을 반환한다. 이는 실제 값(y)이 0일때 $y$값이 1에 가까워 지면 오차가 커진다. 반대로 실제 값(y)이 1일때 $y$값이 0에 가까워 지면 오차가 커진다. 이를 로그 함수를 통해 표현하면 아래와 같은 식이된다.
$\text{if } y=1 → \text{cost}\left( H(x), y \right) = -\log(H(x))$
$\text{if } y=0 → \text{cost}\left( H(x), y \right) = -\log(1-H(x))$
두 식을 그래프로 나타내보자.
</br>
</br>
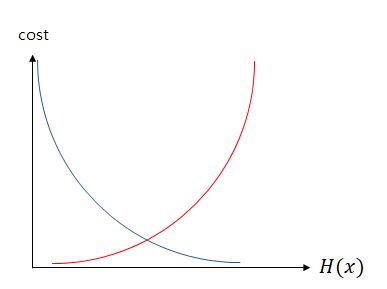
실제값 y가 1일 때는 파란색, 실제값 y가 0일때는 빨간색 선으로 표시했다.
실제값이 1일 때, 예측값인 $H(x)$의 값이 1이면 오차가 줄어든다. 반면에 실제값이 1일 때, 예측값의 값이 0이면 오차가 커진다. 따라서 로지스틱회귀의 손실함수는 $y=0$일때와 $y=1$일때 두개로 나눠진다. 결과적으로 로지스틱 회귀의 손실함수는
$BCE = -\frac{1}{n} \sum_{i=1}^{n} [y^{(i)}logH(x^{(i)}) + (1-y^{(i)})log(1-H(x^{(i)}))]$
- $n$: 데이터의 총 개수
- $y^i$: 데이터 샘플 i의 분류(0, 1)
- $z^i$: 데이터 샘플 i의 logit
- $H(z^i)$: 데이터 샘플 i의 logit의 sigmoid(데이터 샘플 i가 분류에 속할 확률)
이렇게 나타내어 진다. 이 손실함수를 Binary Cross Entropy 함수라고 한다.
$y=0$이면 $ylogH(x^i)$ 가 없어지고,
$y=1$이면 $(1-y^i)log(1-H(x^i)$가 없어지므로 위에 식과 동일하다.
따라서 선형회귀와 마찬가지로 경사하강법을 사용하여 모든 데이터에서 손실을 최소화 하는 $w$와 $b$를 찾을 수 있다.
임계값
로지스틱 회귀의 결과값은 결국 확률이고, 이 확률이 특정 이상이 되면 샘플이 그 그룹에 속할지 말지를 결정할 수 있다. 이 값을 임계값(Threshold)라고 한다.
대부분의 문제에서 기본 임계값은 0.5이지만 필요에 따라 임계값을 변경할 수도 있다.
전반적인 내용은 이게 끝이다. 설명이 길었지만… 결과적으로 keras로 모델을 만들때 활성화 함수로 linear대신 sigmoid로 설정하고, loss만 binary_crossentropy로 바꿔주면 끝난다. 밑에서는 왜 활성화 함수로 sigmoid를 넣어줘야 하는지를 알아보겠다.
번외
활성화 함수로 linear가 아닌 sigmoid를 하는지 알아보자.
로지스틱 회귀분석의 식은 $log(p / (1-p)) = wx + b$ 이렇게 나타내어 진다고 했었다.
위의 식에서 P에 대한 식으로 전개해보자. 수식을 쓰기 귀찮아서 사진으로 대체한다.. $wx + b$를 $Ax + b$라고 생각하면 된다.
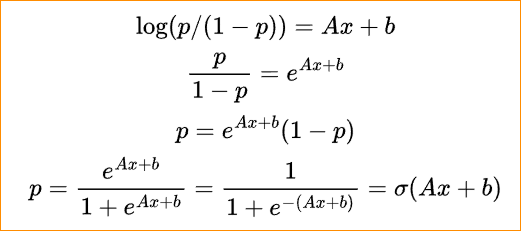
수식을 보면 시그모이드 함수에 가중치를 곱하고 편향을 더한 값을 넣어준다.
결과적으로 로지스틱 회귀 분석의 식은 그냥 선형회귀의 식에 sigmoid함수를 적용한 것과 같다.
댓글남기기