
다중 로지스틱 회귀분석을 해보자!(2편)
저번에는 타이타닉 데이터세트로 회귀분석을 해보았다. 타이타닉 분석
타이타닉 데이터세트는 종속변수의 클래스가 2개(0, 1)였지만 이번에는 클래스가 3개이다.
예측해야할 클래스가 3개일 때, 어떻게 로지스틱 회귀분석을 하는지 알아보자!
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import pandas as pd
import seaborn as sns
데이터 로드
사용할 데이터는 iris(붓꽃)데이터이다.
data는 X에 해당하고, target은 y에 해당한다.
독립변수 종류는 4가지이고(꽃잎과 꽃받침의 가로 세로, 길이),
종속변수는 2개가 아닌 3개이다. 즉 이진분류가 아니다.
iris = load_iris()
print(iris.keys())
print(f"독립변수: {iris.feature_names}")
print(f"종속변수: {iris.target_names}")
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
독립변수: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
종속변수: ['setosa' 'versicolor' 'virginica']
데이터 전처리
데이터와 독립변수의 이름을 가지고 DataFrame형태로 만들어준다.
target(0, 1, 2)의 데이터를 Series형태로 만들고, DataFrame에 추가한다.
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
# target값을 카테고리형 Series 데이터로 저장
species = pd.Series(iris.target, dtype='category')
# 데이터 프레임에 추가
iris_df['species'] = species
데이터 시각화
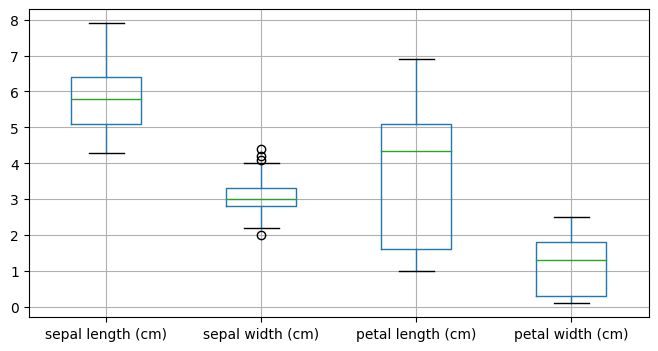
boxplot은 데이터가 어떻게 분포되어 있는지 확인할 때 사용한다. 백분위 기준 25위치를 하단, 75위치를 상단으로한 박스를 그리고, 중앙값을 박스안에 가로선으로 그린다. 최소와 최대값은 박스 바깥쪽 위와 아래에 가로선을 그린다.
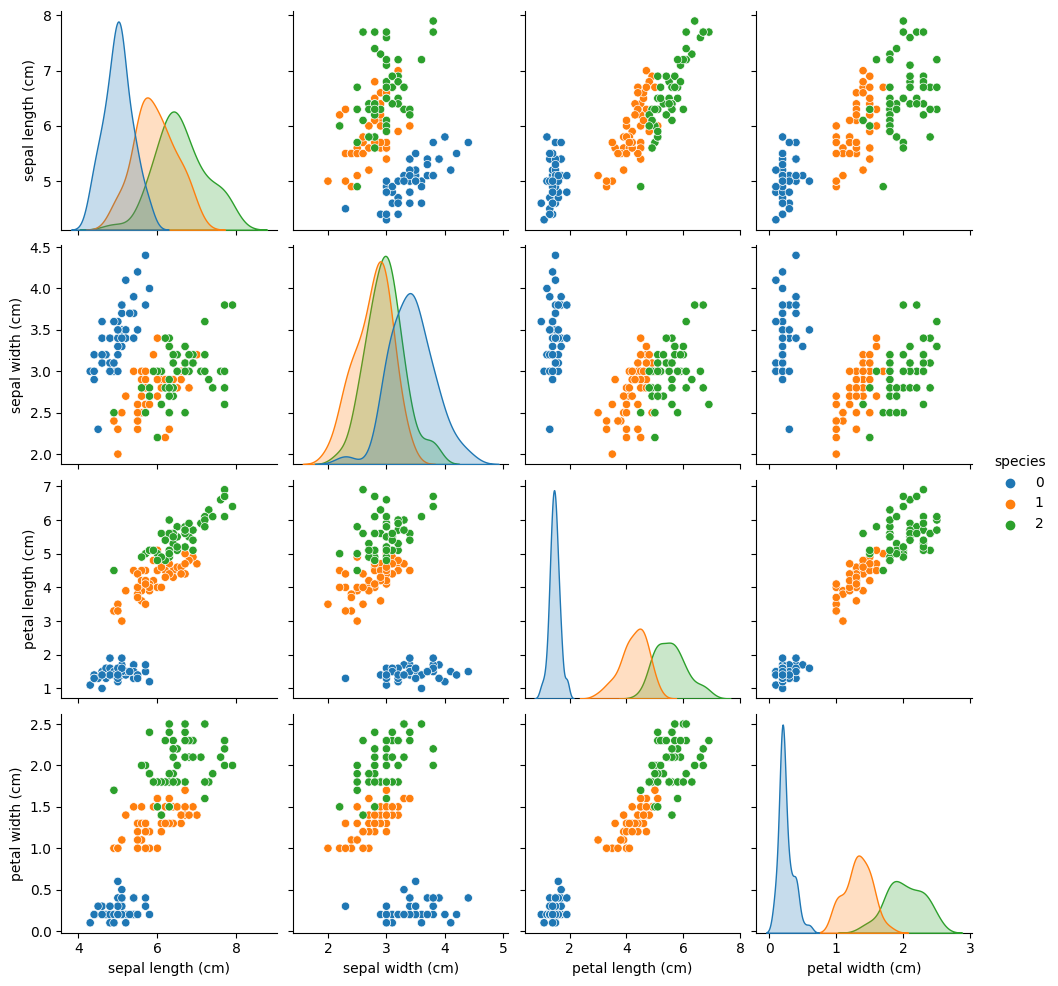
pairplot은 각 그리드의 변수간의 관계를 나타내는 그래프를 그리며, 같은 변수끼리 짝을 이루는 대각선 방향으로는 히스토그램을, 서로 다른 변수끼리는 산점도를 그린다.
iris_df.boxplot(figsize=(8, 4));
iris_df.plot(figsize=(8, 4));
sns.pairplot(iris_df, hue='species');
데이터 생성
X에는 독립변수를 y에는 종속변수를 넣고, 데이터를 분리한다.
stratify는 보통 target값을 지정하는데, target의 class비율을 유지한 채로 데이터를 split한다.
X = iris_df[iris_df.columns[:4]].values
y = iris_df['species']
# stratify: target의 class 비율을 유지 한 채로 데이터 셋을 split 하게 됩니다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y)
훈련
model = LogisticRegression()
model.fit(X_train, y_train)
평가
print(f"Train score: {model.score(X_train, y_train)}")
print(f"Test score: {model.score(X_test, y_test)}")
Train score: 0.9833333333333333
Test score: 0.9666666666666667
예측
X_test의 0번째 데이터를 예측했더니 0이 나왔다. 즉 setosa라는 꽃으로 예측했다. target값이 3개일때, 모델은 어떻게 예측을 하는 것일까?
print(f"예측결과: {model.predict(X_test[0].reshape(1, -1))}")
예측결과: [0]
우선 가중치(계수)와 편향(절편)을 확인해보자.
각 피처에 대한 3가지 클래스의 가중치와 편향이 나왔다.
예를들면, 가중치의 맨 윗줄은 setosa라는 클래스의 피처(4개)만큼 가중치가 나온 것이다.
print(f"가중치: {model.coef_}")
print(f"편향: {model.intercept_}")
# 각 피처에 대한 3가지 클래스의 가중치와 절편
가중치: [[-0.37482545 0.92102175 -2.40684827 -1.02327415]
[ 0.50699472 -0.27596964 -0.21443899 -0.77694677]
[-0.13216927 -0.64505211 2.62128726 1.80022092]]
편향: [ 9.1249249 1.92692326 -11.05184816]
가중치와 편향을 이용해서 결정계수를 구해보자.
가중치와 피처값을 각각 곱해서 더하고, 마지막 편향값을 더한다.
이떻게 계산되는지 느낌만 알고 가자. 어차피 이걸 구해주는 함수가 있다..
sentosa(z1) = (-0.37 * sepal_length) + (0.92 * sepal_width) + (-2.40 * petal_length) + (-1.02 * petal_width) +9.12 == 6.01
versicolor(z2) = (0.50 * sepal_length) + (-0.27 * sepal_width) + (-0.21 * petal_length) + (-0.77 * petal_width) +1.92 == 2.69
virginica(z3) = (-0.13 * sepal_length) + (-0.64 * sepal_width) + (2.62 * petal_length) + (1.80 * petal_width) -11.05 == -8.7
모델 학습이 끝났으면 다양한 메서드를 제공해주는데 그중 decision_function()메서드는 데이터의 결정계수를 구해준다.
decision = model.decision_function(X_test[0].reshape(1, -1))
print(np.round(decision, decimals=2))
[[ 6.01 2.69 -8.7 ]]
그럼 이 결정계수를 가지고 확률을 구할 수 있다.
확률 구하는 식이다. 한번 직접 계산해보자.
$e_{sum} = e^{z1} + e^{z2} + e^{z3}$
setosa_proba(z1) = $e^{z1} \over e_{sum}$
versicolor(z2) = $e^{z2} \over e_{sum}$
virginica(z3) = $e^{z3} \over e_{sum}$
e_sum = np.exp(6.01) + np.exp(2.69) + np.exp(-8.7)
z1 = 6.01/e_sum
z2 = 2.69/e_sum
z3 = -8.7/e_sum
print(z1, z2, z3)
print(np.argmax([z1, z2, z3]))
0.014234448522469039 0.0063711591556475395 -0.020605607678116578
0
대충 눈으로 봐도 0번째 인덱스 값이 제일 크다. 이게 정답이 될것이다.
하지만 또 직접 계산할 필요가 없다. 확률은 말했듯이 sofmax함수를 통해서 각 항목의 총합이 1이 되고, 가장 높은 값이 확률이 정답이 된다.
scipy에서 제공하는 softmax함수에 결정계수를 넣어주면 확률값으로 뱉어준다.
from scipy.special import softmax
proba = softmax(decision, axis=1)
print(np.round(proba, decimals=3))
print(np.argmax(proba))
[[0.965 0.035 0. ]]
0
X_test의 0번째 인덱스는 setosa일 확률이 96퍼센트이다.
오늘의 정리
로지스틱 회귀에서 클래스가 3개 이상일때는, softmax를 사용해서 확률을 구한다는 것을 알아두자!
댓글남기기