
LSTM 논문리뷰
원문링크: LONG SHORT-TERM MEMORY
Introduction
Long Short-Term Memory(LSTM) 논문은 딥러닝 분야, 특히 RNN(Recurrent Neural Networks) 분야에서 중요한 논문이다. Sepp Hochreiter와 Jürgen Schmidhuber가 1997년에 출판하였다.
저자는 전통적인 RNN에서 발생하는 기울기 소실 문제를 해결하는 새로운 유형의 RNN 아키텍처를 제안했다. 기울기 소실(gradient vanishing)이란 기울기가 너무 작아서 수렴이 느려지거나 전혀 수렴되지 않는 것을 말한다.
LSTM 아키텍처는 정보를 장기간 저장할 수 있는 “메모리 셀”과 셀 안팎으로 정보의 흐름을 조절하는 게이트를 사용한다. 이를 통해 네트워크는 장기적인 종속성을 더 잘 보존할 수 있으므로 순차 데이터와 관련된 작업의 성능이 향상된다.
LSTM은 자연어 처리, 음성 인식 및 시계열 예측을 비롯한 다양한 분야에서 널리 사용된다.
RNN(Recurrent Neural Network)
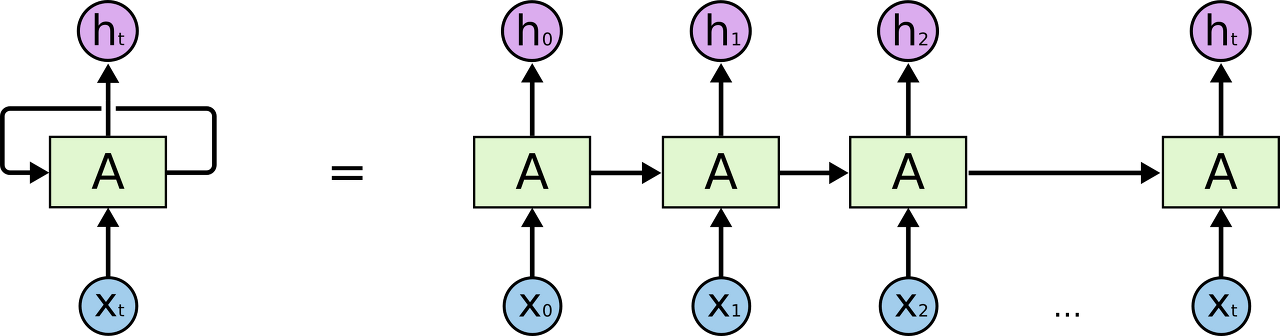
위 그림은 RNN을 나타낸 것이다.
A는 RNN 블록이고, input으로 $x_t$를 받아서 output으로 $h_t$를 내보낸다. 이걸 반복하는 것이다. RNN은 스스로를 반복하면서 이전 단계에서 얻은 정보(값)을 참고한다.
쉽게 생각해서 RNN이라는 layer를 계속 반복해서 순서대로 정보를 전달하는 것으로 생각하면 된다.
그렇기 때문에 sequence데이터나 list데이터를 다루기에 최적화된 구조인 것이다.
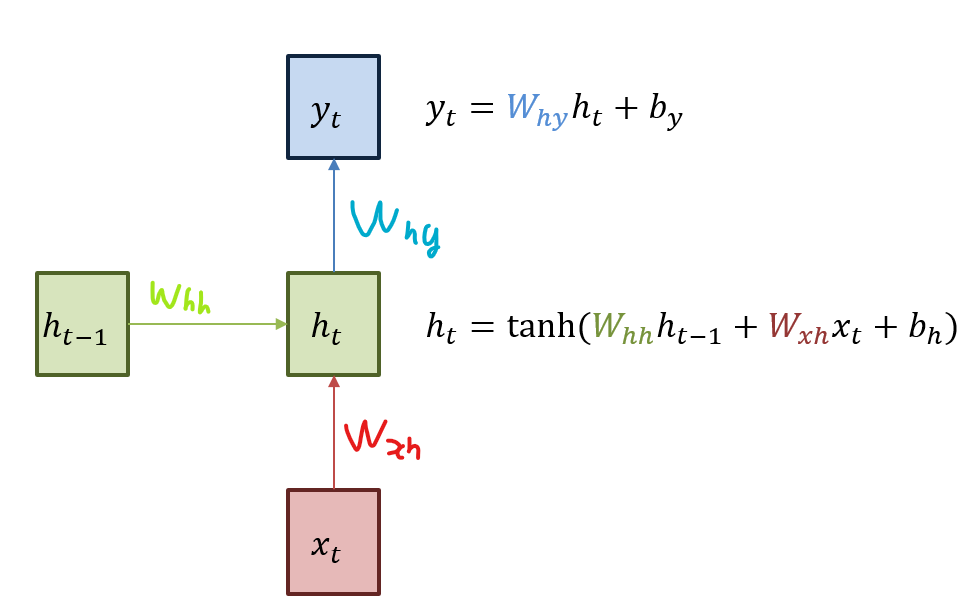
조금 더 자세히 살펴보자. 녹색 박스는 hidden state를 의미한다. 빨간색 박스는 input, 파란색 박스는 output이다. 현재 상태의 $h_t$는 이전 시점의 $h_{t-1}$을 받아 갱신된다.
$x_t$와 가중치 $W_{xh}$를 계산해서 h_t에 넘겨주고, $h_t$는 $x_t$에서 넘어온 값과 $h_{t-1}$과 가중치 $W_{hh}$를 계산해서 $tanh$에 넣어 계산한다. $y_t$는 $h_t$에서 넘어온 값과 가중치 $W_{hy}$를 계산해서 최종 output으로 반환한다. 따라서 학습 파라미터는 각 가중치가 되겠다. (중간에 바이어스도 계산한다)
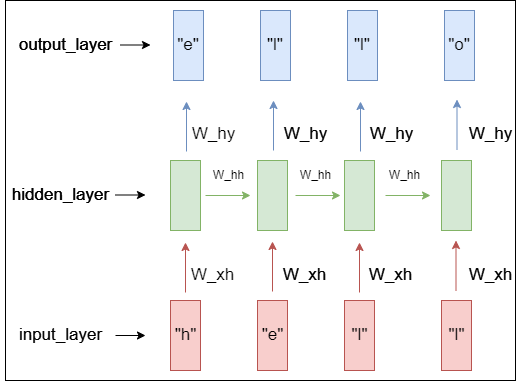
대충 이런 느낌으로 동작한다. input에 ‘hell’이라는 단어가 들어갈 때, output으로 ‘o’가 반환되게 하는 예시이다. input_layer에는 원핫벡터 데이터가 들어갈 것이고, hidden_layer는 값들이 들어있을 것이다. output_layer에는 정답으로 예측되는 원핫벡터가 있을 것이다.
RNN의 문제
RNN은 짧은 의존기간만 가지고 있다. 위의 사진처럼 ‘hell’이라는 sequence가 들어왔을 때는, 필요한 정보를 얻기 위한 시간 격차가 크지 않기 때문에 RNN에서도 쉽게 가능하다.
하지만 긴 sequence가 들어오고, 필요한 정보를 얻기 위한 시간 격차가 클때, 즉 더 많은 정보를 예측에 필요로 할때, 문제가 발생한다는 것이다.
사진으로 설명하면, $h_{t+1}$을 예측하는데, ${x_0}$과 ${x_1}$의 정보는 참고를 못한다는 뜻이다.
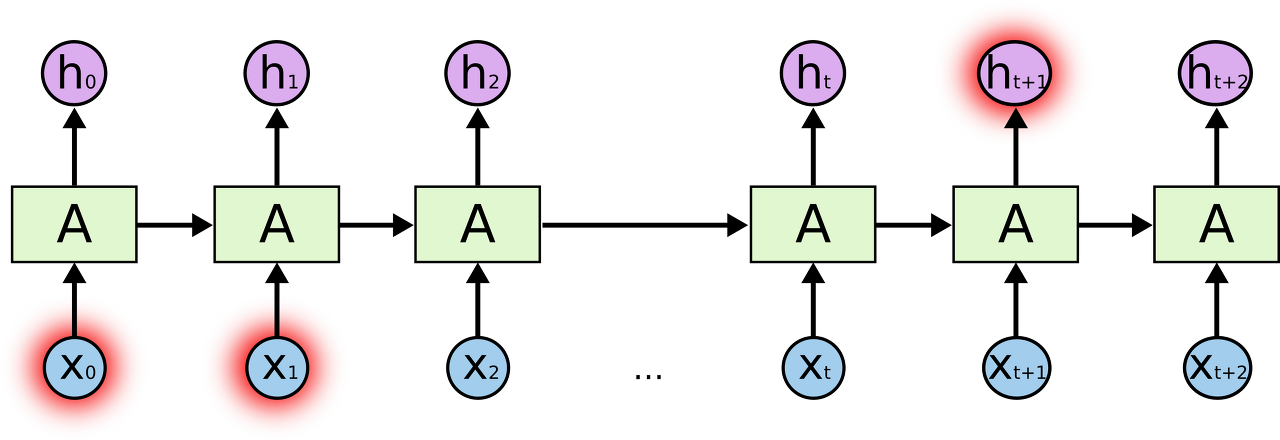
이 문제를 해결하기 위해 장기 의존 기간을 필요로 하는 모델을 만든것이 LSTM이다.
LSTM
LSTM(Long Short-Term Memory)은 RNN(Recurrent Neural Network)의 한 유형으로 기존 RNN에서 기울기가 사라지는 문제를 해결하도록 설계되었다.
RNN에는 하나의 layer만 사용한것에 반해, LSTM Layer에는 4개의 layer를 사용하였다.
LSTM은 메모리 셀(cell state)이라고 하는 각 장치가 있다.
메모리 셀은 입력 게이트, 망각 게이트 및 출력 게이트의 세 가지 게이트로 이루어져 있으며, 게이트는 메모리 셀 안팎으로의 정보 흐름을 제어하여 네트워크가 순차 데이터의 장기적인 종속성을 보존할 수 있도록 한다.
얘네들이 서로 상호작용하며 특별한 방식으로 정보를 주고 받는다.
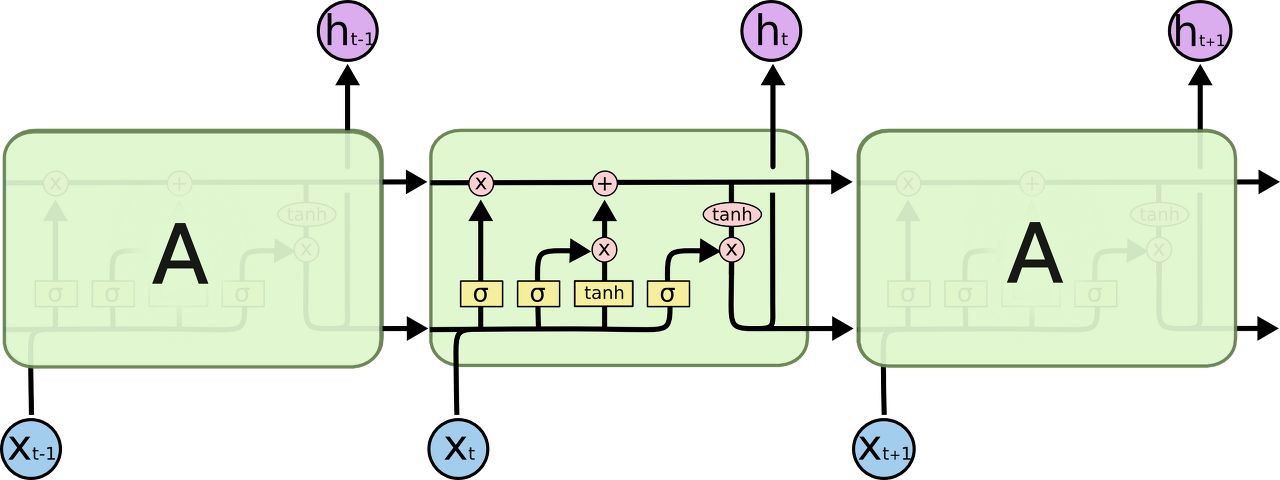
그림에서 노란색 박스는 layer를 나타내고, 분홍색 동그라미는 연산을 나타낸다. 선들은 정보가 어떻게 이동하는지 나타낸 것이다.
Forget Gate
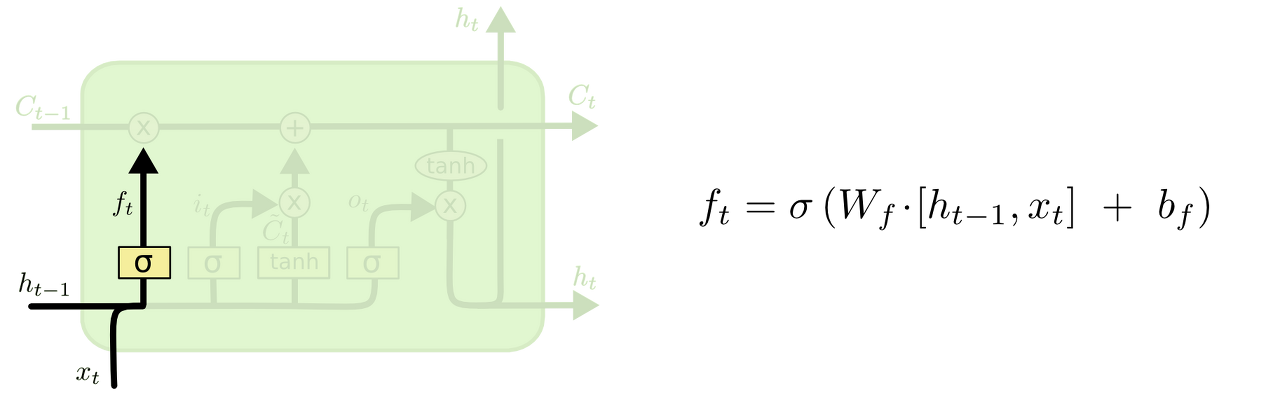
LSTM의 첫 단계로는 들어온 정보로 부터 어떤 정보를 버릴 것인지 정하는 단계이다. 따라서 이 단계를 forget gate라고 부른다. 정보는 sigmoid에 의해 결정되고, $h_{t-1}$과 $x_t$를 받아서 0과 1사이의 값을 메모리 셀에 넘겨준다. sigmoid의 값이 1이면 정보를 보존하고, 0이면 정보를 버린다.
Input Gate
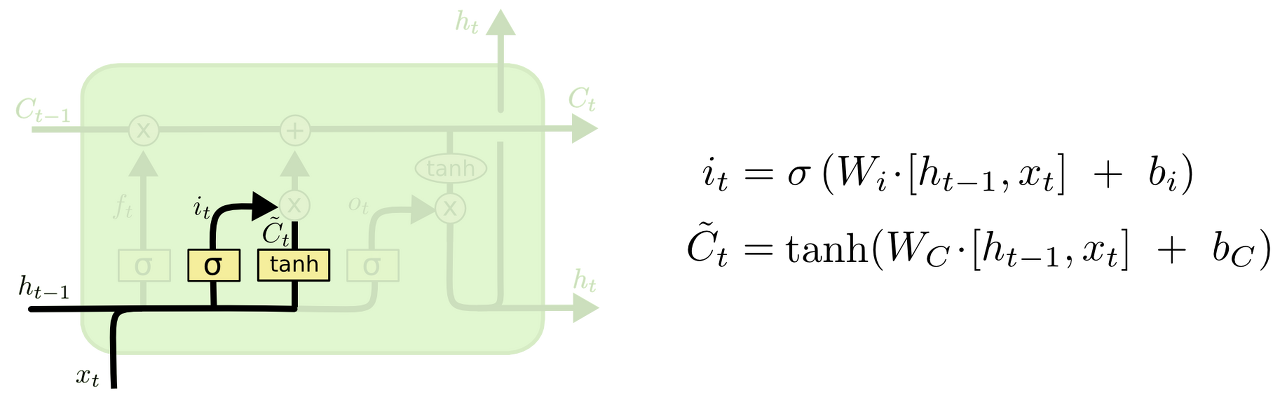
입력 게이트는 새로 들어오는 정보가 메모리 셀에 저장되는 정도를 결정하는 단계이다. 입력 데이터를 기반으로, 계산결과의 영향력을 의미한다. tanh는 RNN과 동일하게 단어의 뜻을 파악하는 부분이고, sigmoid는 그 결과를 메모리 셀에 얼마만큼 반영할 지 정도를 나타낸 것이다.
Memory Cell
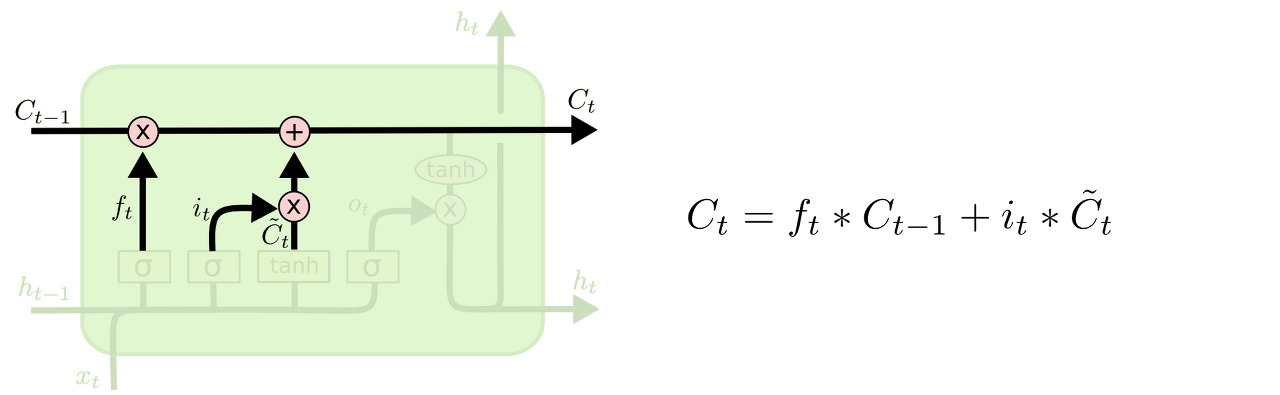
메모리 셀은 쉽게 말해서 입력 게이트의 정보와 망각게이트의 정보를 저장하는 곳이다. 이 정보는 다음 단계에서 활용되고, 입력 게이트와 망각 게이트에서 나온 정보를 바탕으로 업데이트 된다. RNN에서 hidden state만으로 정보를 전달한 것과는 달리, 어떤 정보가 필요없는지, 중요한지 그런 의미를 전파한다고 생각하면 된다.
Ouput Gate
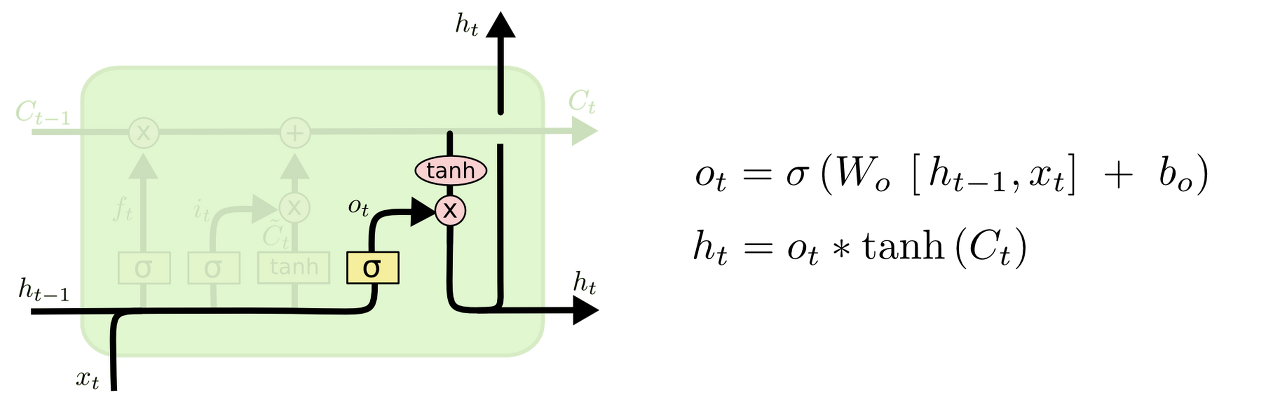
output Gate는 무슨 정보를 출력으로 반환할 지 정하는 단계이다. output은 메모리 셀의 정보를 바탕으로 필터링 된 값이다. 먼저 sigmoid에 $h_{t-1}$과 $x_t$를 넣고 계산해서 메모리 셀의 어떤 부분을 output으로 내보낼 지 정한다. 그 다음 tanh에 메모리 셀에 저장된 정보를 넣고 sigmoid값과 곱해서 최종 output을 계산한다. output은 출력과 동시에 다음단계로 정보를 넘긴다.
느낀점
메모리 셀이 제일 중요한 것 같다. 기억해야할 정보와 버려야할 정보를 정해줌으로써, 이전에 모든 정보를 참고하는 RNN의 기울기 소실문제를 해결한 것 같다.
메모리 셀은 이전 정보인 h를 통해 sigmoid를 하고 이번 정보의 결과인 tanh 값에도 가중치를 두어 비율을 가지게 한다. 그래서 forget gate에서 메모리 셀의 값이 손실이 일어난다고 해도 메모리 셀에 있는 정보의 비율은 다 다르게 만들어 진다. 이렇게 갱신된 정보를 가지고 있는 메모리 셀에 tanh를 계산한다. 이렇게 되면, 메모리 셀에는 이전의 정보와 새로운 정보가 모두 들어있게 되는데, 이 정보를 또 sigmoid로 가중치를 주어 최종 결과로 뱉는 것이다.
이 과정이 계속 반복되는 것이다. 내용이 많이 어렵긴 한데, 딥러닝에서의 학습은 x와 y값의 차이를 줄이는 가중치와 편향을 구하는 것이다.
LSTM의 기본 동작만 알아두고, 결국은 LSTM도 target을 찾기 위해 손실이 최소화 되게끔 가중치와 편향을 찾는 과정이고, 그 값을 RNN보다 더 향상된 방법으로 찾는 모델이라고만 알아두자.
댓글남기기