
VAE 논문리뷰
Abstract
본 논문은 다루기 힘든 사후 분포와 대규모 데이터 세트가 있는 연속 잠재 변수가 있는 상황에서 방향성 확률 모델에서 효율적인 추론과 학습을 어떻게 수행할 수 있을까? 란 질문에서 시작된다. 우리는 큰 데이터셋에도 확장할 수 있고 가벼운 미분가능성 조건이 있다면 계산이 불가능한 경우에도 작동하는 stochastic variational inference and learning 알고리즘을 제안한다. 첫째, variational lower bound의 reparameterization이 표준적인 stochastic gradient 방법론들을 사용하여 직접적으로 최적화될 수 있는 lower bound estimator를 만들어낸다는 것을 보였다. 둘째, 각 datapoint가 연속형 잠재 변수를 가지는 i.i.d.(독립항등분포) 데이터셋에 대해서, 제안된 lower bound estimator를 사용해 approximate inference model(또는 recognition model이라고 불림)을 계산이 불가능한 사후확률에 fitting 시킴으로써 사후 추론이 특히 효율적으로 만들어질 수 있다는 점을 보인다.
Introduction
VB(variational Bayesian) 접근 방식은 다루기 힘든 사후확률에 대한 근사의 최적화를 포함한다. 불행히도 일반적인 mean-field 접근 방식은 대략적인 사후확률에 대한 기댓값의 분석적 해를 요구하며, 일반적인 경우에 이 또한 계산 불가능하다. 논문에서는 variational lower bound의 reparameterization가 lower bound의 단순한 미분 가능한 편향되지 않은 추정치를 산출하는 방법을 보여준다. 이 SGVB(Stochastic Gradient Variational Bayes) estimator는 연속형 잠재 변수나 파라미터를 가지는 어떤 모델에서도 효율적인 근사 사후추론를 위해 사용될 수 있으며, 표준 gradient ascent 기법을 사용해서 직접적으로 최적화한다.
i.i.d 데이터셋과 데이터포인트당 연속적 잠재변수의 경우, AEVB(AutoEncoding VB) 알고리즘을 제안한다. AEVB 알고리즘에서 우리는 SGVB 추정기를 사용하여 인식 모델을 최적화함으로써 추론 및 학습을 특히 효율적으로 만든다. 이 모델을 사용하면 간단한 샘플링을 사용하여 매우 효율적인 근사 사후 추론을 수행할 수 있다. 학습된 근사 사후 추론 모델은 인식, 잡음 제거, 표현 및 시각화 목적과 같은 다양한 작업에도 사용할 수 있다. 신경망이 인식 모델에 사용될 때, 우리는 Variational Auto-encoder에 도달한다.
VAE의 목표
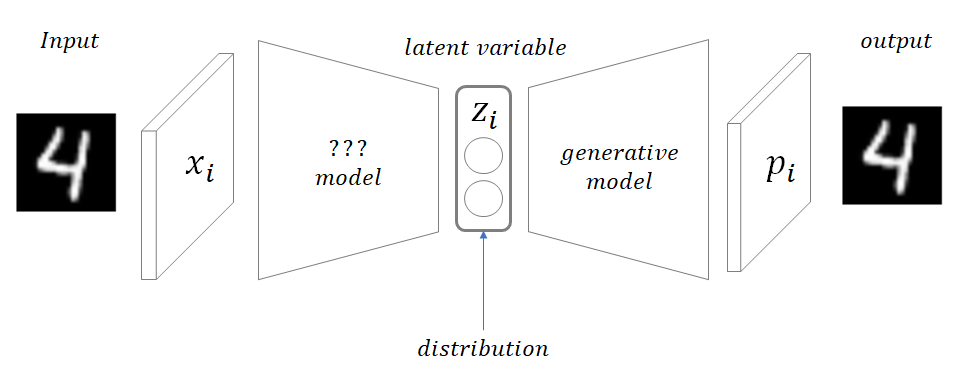
VAE는 오토인코더와 목적이 전혀 다르다. 오토인코더는 어떤 데이터를 잘 압축하고 특징을 잘 뽑는지의 관한 encoder에 중점을 둔 모델이고, VAE는 Generation model로 어떤 새로운 데이터를 잘 만들어 내는지에 관한 decoder에 중점을 둔 모델이다. VAE는 이미지 데이터의 확률 분포를 이용해 어떤 새로운 데이터를 생성하는 것이 목표이다.
VAE의 구조
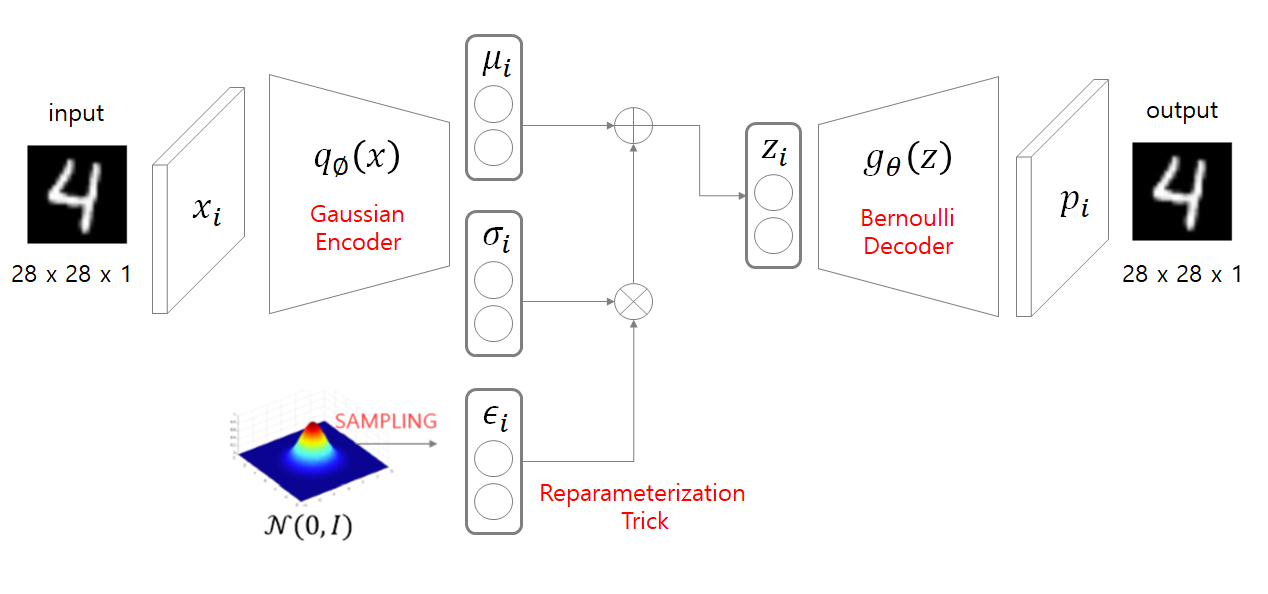
데이터가 encoder를 통과하면 평균과 표준편자 두개의 값을 output으로 내는데, 평균과 표준편차를 알면 정규분포를 만들수 있다. 이 분포에서 z를 샘플링하고 디코더를 통과하여 input과 비슷한 분포를 가진 데이터를 생성할 수 있다. 하지만 샘플링은 랜덤성을 띄기 때문에 계산이 불가능한데, 이를 reparameterization trick을 사용하여 계산이 가능하게 만든다.
- input: $x_i$ -> $q_\phi(x)$ -> $\mu_i$, $\sigma_i$
- $z_i$: $\mu_i$, $\sigma_i$, $\epsilon_i$
- output: $z_i$ -> $g_\theta(z)$ -> $p_i$
Reparameterization Trick
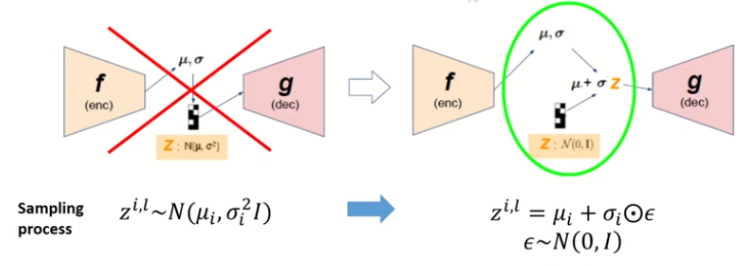
VAE에서 쓰는 방법이 인코더를 통과하면 $\mu$ 와 $\sigma$ 를 뽑고 그것을 이용해서 정규 분포를 만들어서 샘플링을 해서 $z$를 만드는 것이다. 하지만 이 방법은 미분이 불가능하기 때문에, 평균이 0, 표준편차가 1인 표준정규분포에서 $\epsilon$ 을 샘플링한 뒤, 그것을 표준편차에 곱해주고 평균에 더해주면 새로운 샘플링 값이 된다. 이렇게 되면 $z$ 는 사진과 같은 식이 되고 미분이 가능하게 만들어진다.
Loss fuction의 이해
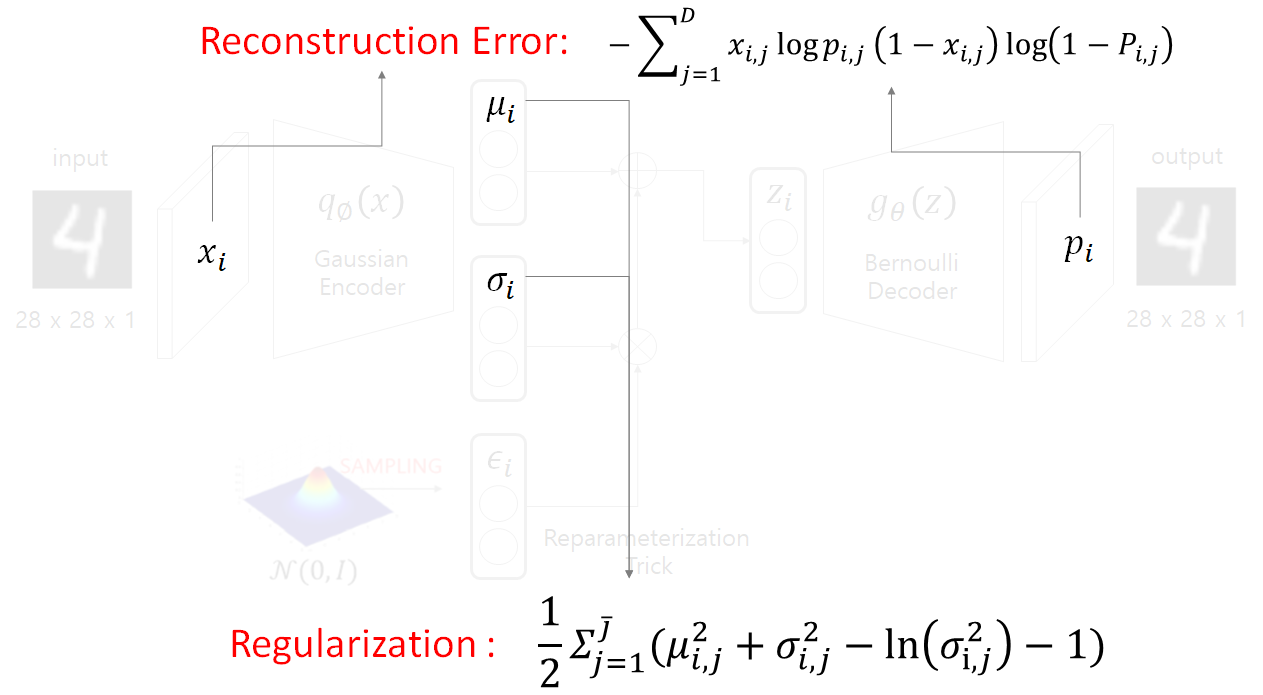
vae에서는 손실함수가 두개이고 두개의 합으로 나타내어 진다. Reconstrction Error는 확률은 정규분포로 가정하냐, 베르누이로 가정하냐에 따라 두가지가 있다.
정규분포로 가정하면 MSE로 정의하고 베르누이로 가정하면 cross entropy loss로 정의하는데, 본 논문에서는 cross entropy loss를 사용하였다. Regularization은 $z_i$ 가 정규분포내에서 샘플링을 하기 때문에 $z_i$ 가 정규분포를 따라야 한다는 가정에서 도출된 식이다. 즉 인코더를 통과해서 나온 z의 확률분포와 원래 정규분포와의 거리를 최소화 시키는 KL Divergence의 식이 된다. 자세한것은 여기 참고
도메인 지식
지금부터 loss function이 도출된 원리를 식으로 살펴볼건데 식을 이해하기 위해서 몇가지의 지식이 필요하다.
- Kullback-Leibler Divergence(KLD)
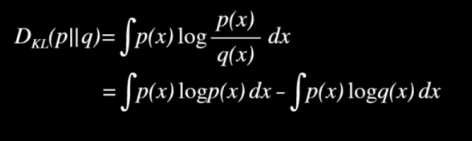
- 두 확률 분포의 다름의 정도를 나타내는 함수
- 항상 0 이상의 값을 지님
- 두 분포가 같을 때 값이 0, 분포가 다를수록 값이 커짐
- 두 분포가 가우시안 분포를 따를 경우 간략하게 표현이 가능
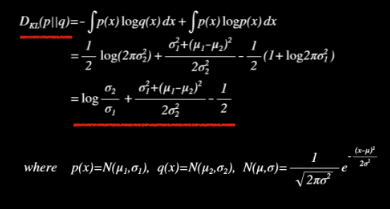
자세한 것은 KLD 참고
- Bayes Rule(베이즈 정리)
주어진 현 사건 $E$ 에 대해서 $H$ 가 발생할 믿음
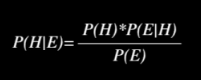
- E는 사건, H는 가설
- $P(H)$ : 사전에 알고 있는 $H$ 가 발생할 확률
- $P(E)$ : $E$ 에 대한 사전확률. $E$ 가 발생할 확률
-
$P(H E)$ : $E$ 가 주어졌을 때, $H$ 가 발생할 사후 확률 -
$P(E H)$ : 모든 사건 H에 대한 $E$ 가 발생할 가능도(likelihood)
자세한 것은 베이즈정리 참고
- Monte Carlo Approximation(몬테 카를로 추정)
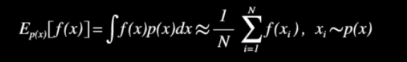
확률 밀도 함수 $p(x)$ 를 따르는 $x$ 에 대한 $f(x)$ 의 기대값은 $p(x)$ 를 따르는 샘플들로 근사할 수 있다.자세한 것은 몬테카를로추정 참고
Loss function의 배경
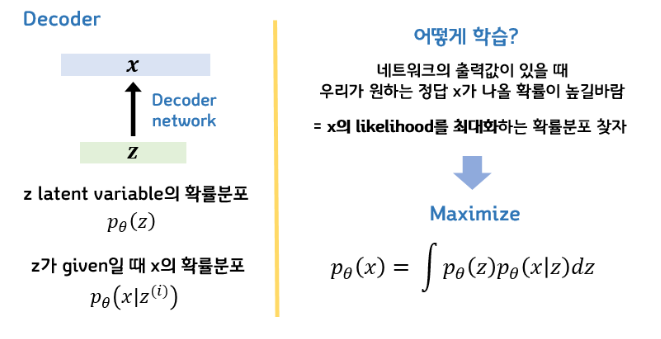
잠재변수인 $z$ 의 확률분포를 $p(z)$ 라고 하고 $z$ 가 주어졌을 때 $x$ 의 확률분포를 $p(x|z)$ 라고 해보자. VAE의 목표는 입력데이터의 분포를 근사하는 모델을 생성하는 것인데, 이 말은 어떤 네트워크의 출력값이 있을 때 우리가 원하는 정답인 $x$ 가 나올 확률이 높길 바라는 것이라고 할 수 있다. 따라서 $x$ 의 가능도(likelihood)를 최대화 하는 확률 분포를 만들고 싶은 것이 목적이 된다. 즉 $p(x)$ 를 최대화 하고 싶은 것이기 때문에 $p(x)$ 를 적분식으로 표현하면 $p_\theta(x) = \int p_\theta(z)p_\theta(x|z)dz$ 가 된다. (여기서의 $\theta$ 는 신경망의 파라미터이다) 위 공식은 베이즈 정리를 통해 나온 식으로, $x$ 와 $z$ 가 동시에 일어날 확률을 모든 $z$ 에 대해서 적분했다는 의미로 결국 $x$ 의 가능도가 된다.
Variational Inference
수식이 도출되었으면 계산을 해야 하는데 P(z) 는 분포가 가우시안을 따른다고 가정하면 구할 수 있고, $p(x|z)$ 는 디코더의 출력에 해당하기 때문에 신경망으로 만들 수 있다. 하지만 모든 $z$ 에 대해서 적분하는 것이 불가능 하기 때문에 계산이 안된다. 그래서 본 논문에서는 인코더를 사용하여 사후 확률 분포 $p(z|x)$ 를 가장 근사화하는 $q(z|x)$ 를 구하게 된다. ($p$ 는 알고싶은 true값, $q$ 는 $p$ 를 근사화하는 추정값 이라고 생각하면 된다)이러한 생각을 Variation Inference라고 한다.
ELBO 도출
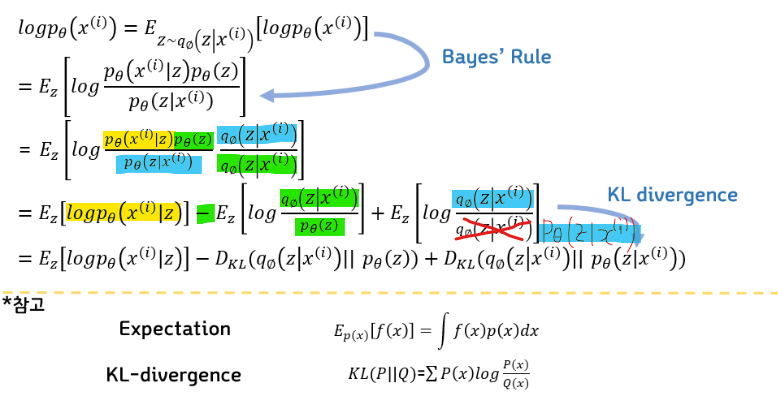
먼저 $p(x)$ 를 최대화 시키는 것이 목표이다. 첫번째 줄에서는 계산을 쉽게 하기위해서 $p(x)$ 에 $log$ 를 씌우고 기대값 형태로 나타낸다. 기대값은 $z$ 가 encoder를 거져서 나오는 확률 분포를 따를 때의 기대값이다. 두번째 줄에서는 베이즈 정리를 이용해서 식을 변경한다. 세번째 줄에서는 분모분자에 같은 값을 곱해서 $log$ 안의 분수를 덧셈 뺄셈 형태로 변환한다. 같은 값을 곱하는 이유는 일종의 트릭인데, 저 부분은 값이 1인데 저걸 이용해서 계산할 수 없는 error를 나눠줄 수 있기 때문이다. 4번째 줄에서는 수식이 KLD와 형태가 같기 때문에 KLD로 바꿔주면 최종 식이 된다.
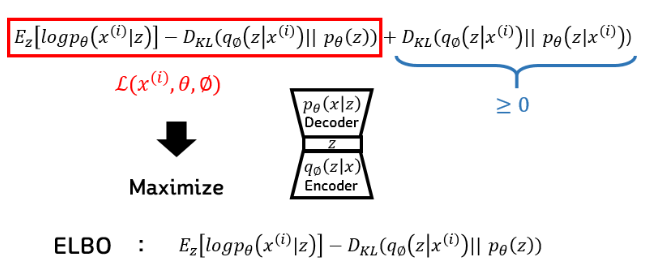
최종 목표는 맨 뒤의 수식을 최소화 하는 것인데, 여기에서도 $p(z|x)$ 의 값은 구할 수 없다. $x$ 가 주어졌을 때, $z$ 의 true 값을 알 수 없기 때문이다. 하지만 우리는 이 식이 KLD라는 것을 알고 항상 0보다 크거나 같다는 정도는 알기 때문에, 앞의 부분을 Lower Bound로 해서 최대화를 시켜주면 전체 식을 최대화 한것과 같다는 결론이 나온다. 베이즈 정리에서 Evidence에 해당되는 $x$ 에 대한 확률(Marginal Likelihood)을 구하는 것이기 때문에 Evidence LowerBOund 라고 해서 ELBO라고 불린다.

보통 최적화에서는 minimization을 하기 때문에 ELBO앞에 -를 붙여주었고, 그 값을 최소화하는 $\theta$ 와 $\phi$ 를 찾아주면 된다. 여기서의 각 term은 두 가지로 구분이 된다.
- Reconstruction error 어떤 input $x$ 가 들어왔을 때 output으로 $x$ 가 나올수 있게 하는 term이다. 다시말해서 $x$가 들어오면 인코더 $q_\phi()$를 지나서 $z$가 나오게 되고, 그 $z$를 디코더 $g_\theta()$에 넣어서 x가 나올 확률을 최대화 하는 term이다.
- Regularization $x$가 인코더 $q_\phi()$를 지나서 나온 $z$와 우리가 가정한 $z$의 분포와 최대한 가깝게(일치하게) 만드는 term이다.
Regularization 계산

Regularization 계산을 위해서 본 논문에서는 두 가지 가정을 한다. 첫 번째는 인코더를 통과해서 나온 분포는 covariance가 diagonal한 multivariate 정규분포를 따른다는 것이 가정1이다. 가정2는 조금더 단순하게 해서 평균이 0, 표준편차가 1로 표현이 되는 p를 가정하는 것이다. 즉 인코더를 통과하면 multivariate 정규분포를 따르지만 z에 대한 분포는 (0,1)인 정규분포를 따른다고 가정한 것이다. KLD를 사용하여 이 두개의 가정을 같게 해주면서 최적화를 시킬 수 있다.

우리는 p(z)를 평균이 0, 표준편차가 1인 정규분포라고 가정을 했기 때문에 KLD식에서 평균과 표준편차에 해당하는 값들에 모두 0과 1을 넣고 식을 정리하면 최종적으로 인코더를 통과한 뮤와 시그마만 남기 때문에 Regularization를 계산할 수 있는 것이다.
Reconstruction error 계산
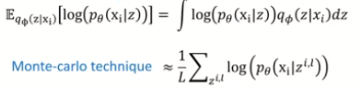
Reconstruction error는 기대값 형식으로 되어있기 때문에 적분이 가능하다. 하지만 모든 z에 대해서 적분은 쉽지 않다. 따라서 이때 등장하는 것이 몬테 카를로 추정이다. 쉽게 말하면 어떤 분포를 가정하고 그 분포에서 무한개의 샘플링을 해서 평균을 내면 그것이 실제 true 기대값과 거의 동일해 진다는 가정이다. 실제로 무한개의 샘플링을 할 수 없고, 시간이 오래 걸리기 때문에 여기서 L을 1로 가정한다. 즉, 랜덤하게 하나만 샘플링해서 그 값을 사용하는 것이다. 하지만 여기에서의 식 또한 확률분포로 표현이 되어 있기 때문에 계산을 하기 위해서 두 가지의 가정을 이용해서 식을 변형한다.
- Bernoulli Distribution

베르누이 분포를 따른다고 가정했을 때, 각 차원별로 확률을 계산하기 때문에 곱하기로 표현이 가능하고, $log$로 인해서 곱셈이 합으로 표현 가능해진다. 그리고 $p_\theta$ 식을 베르누이 식으로 변형한 뒤 정리하면 cross-entropy식이 나오게 된다 - Gaussian Distribution

가우시안 분포를 따른다고 가정하면 $\mu$ 와 $\sigma$ 는 디코더가 내주고 가우시안 식으로 전개 후, $\sigma$ 가 1이라는 가정하에 squared Error 식으로 표현이 가능하다.
따라서 기본적으로 인코더는 가우시안 분포를 따르지만 Reconstruction error의 식만 바꿔주면 두가지의 VAE 구조를 만들 수 있다.
Experiments
MNIST 데이터셋 및 Frey Face 데이터 세트에서 이미지의 생성 모델을 훈련하고 ELBO및 Marginal likelihood 측면에서 학습 알고리즘을 비교하였다.
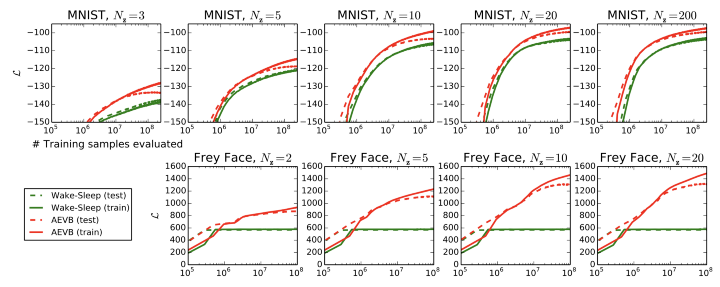
위 그림에서 보는 것처럼 잠재 공간이 바뀜과 관련없이 전체적으로 Marginal likelihood가 더 높게 나타남을 보여주었다.
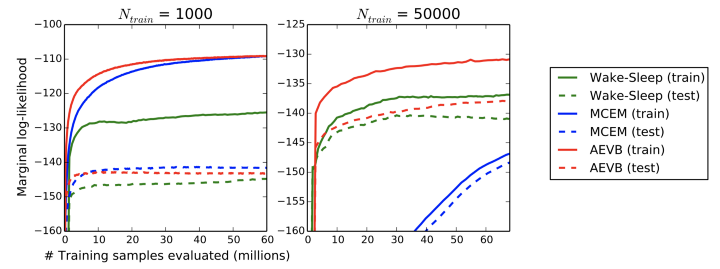
마찬가지로 몬테카를로 추정과 함께 training dataset size에 따른 비교도 진행하였는데, 이 역시 높은 marginal likelihood를 보여주었다.
댓글남기기