
AnoGAN 논문리뷰
원문링크: Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery
1. Abstract
질병 진행 및 치료 모니터링과 관련된 라벨링된 이미지를 탐지하는 모델은 구하기가 힘들다. 모델은 일반적으로 자동탐지를 하는데 많은 anotation과 label이 필요하다. 이는 많은 제약사항이 있다. 따라서 이 논문에서는 비지도학습을 이용해서 이미지 안에서 이상을 탐지하는 방법을 수행한다. 본 논문에서는 이미지 공간에서 잠재 공간으로의 매핑을 기반으로하는 anomaly score를 계산하는 AnoGAN을 제안한다. 새로운 데이터가 들어오면 이상이라고 판단하는 부분에 labeling을 하고 학습되어 있는 분포에 대한 image pathch에 대한 anomaly score를 매긴다. 이 방식은 망막 또는 과반사 초점을 포함하는 이미지와 같은 비정삭적인 이미지를 올바르게 판단하는 것을 확인하였다.
2. AnoGAN의 학습 방법
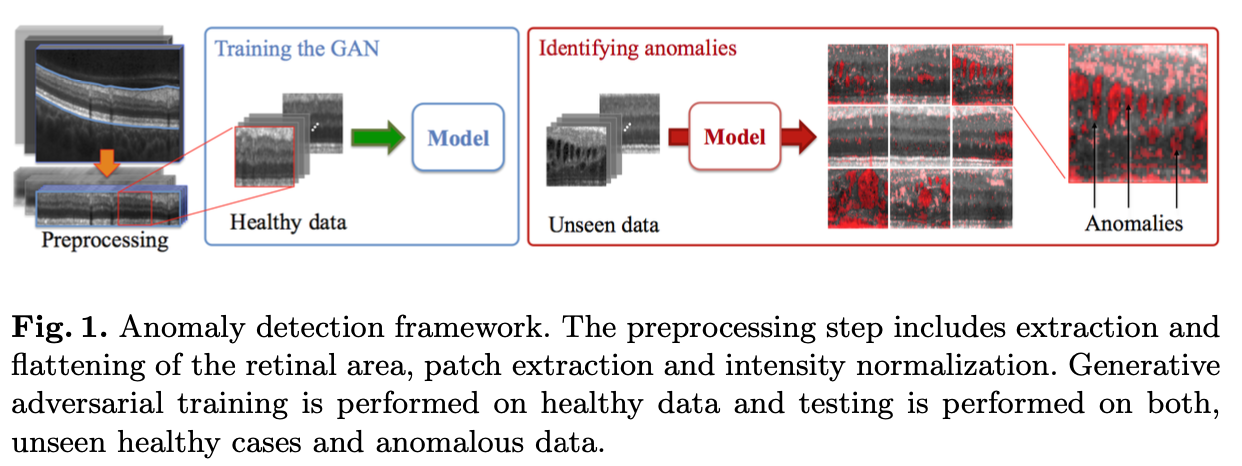
그림과 같이 GAN모델에는 Healthy data만 입력하여 정상 이미지에 대한 분포를 학습한다. 학습된 모델에는 정상/비정상 이미지를 함께 입력하여 이상을 분류한다.
2.1 GAN의 동작 원리
GAN에 대해서는 추후 포스팅 예정입니다. 지금은 우선 간단하게 동작 원리만 살펴보고 넘어가겠습니다.
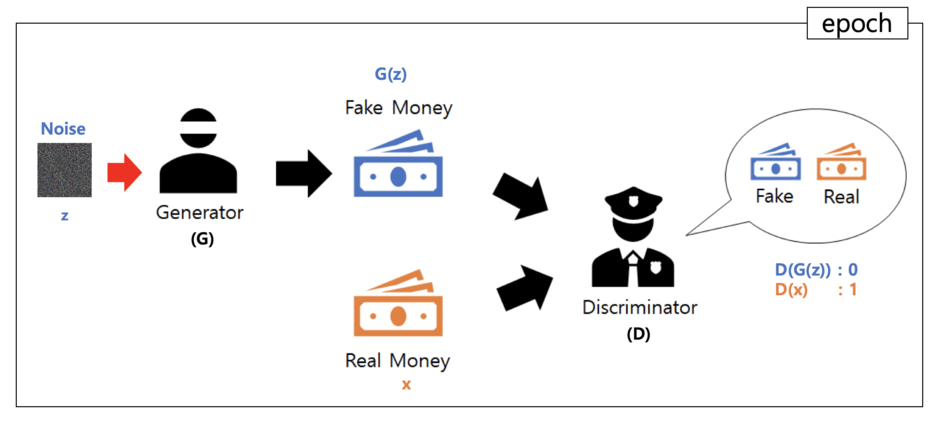
Generator 학습
Latent Space에서 Random Sampling을 한 Z값을 Generator에 input으로 넣어 Fake Image를 생성한 후, Discriminator에 input으로 넣어 True가 나오게 학습을 진행한다
Discriminator 학습
Discriminator에 정상이미지를 input으로 넣어 True라고 학습을 진행하고 G(z), 즉 Generator가 생성한 Fake Image를 input으로 넣어 False라고 학습을 진행한다
GAN Loss
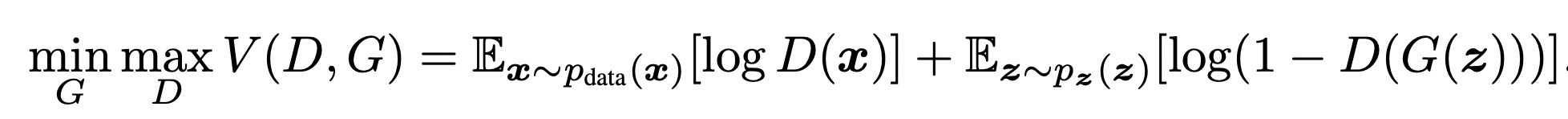
Discriminator는 V가 최대가 되도록 학습하고, Generator는 V가 최소가 되도록 학습한다.
2.2 AnoGAN의 동작 원리
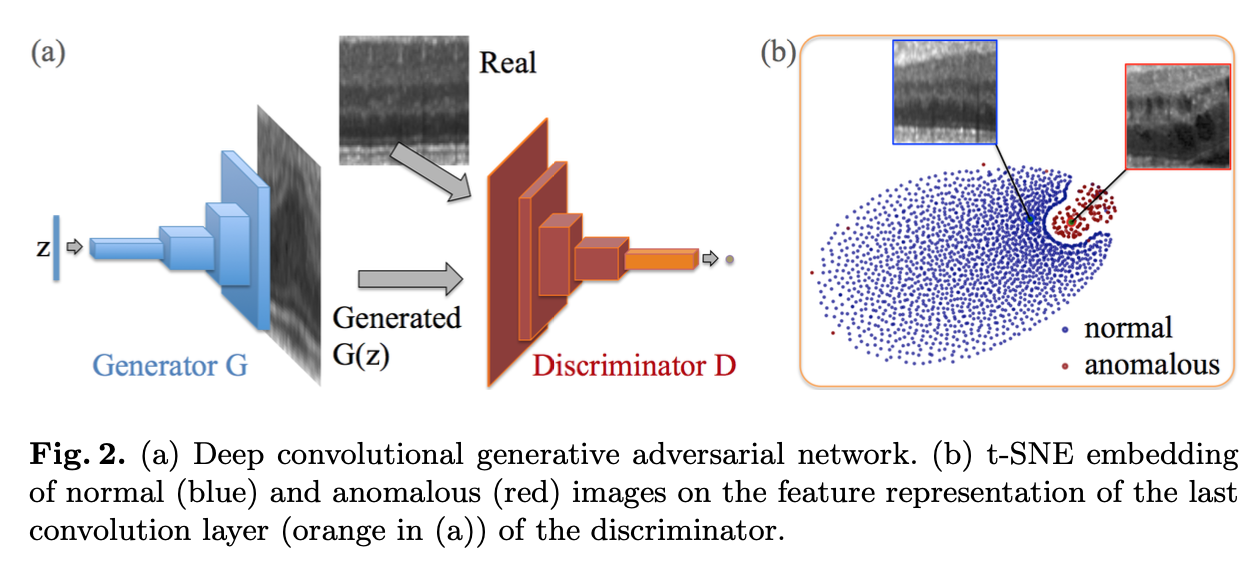
Generator 학습
정상 데이터의 Manifold를 학습한다. Anomaly Detection을 수행하기 위한 이미지는 z로 생성하는 것이 아니라 Real Image(X)를 사용해야 하기 때문에 AnoGAN에서의 Generator는 GAN과 다르게 Z에서 X를 생성하는 것이 아닌, X의 분포를 Z로 매핑하는 과정이 필요하다. 결국은 Fake Image를 만들어 내지만 Real Image의 분포를 참고한 Fake Image를 만들어내게 된다.
Discriminator 학습
Discriminator에 Real Image만 input으로 넣어 True라고 학습을 진행한다
AnoGAN Loss Function
Loss를 구하기 전에 정상 데이터로만 학습을 진행한 DCGAN이 필요하고 Generator와 Discriminator의 parameter들은 고정을 시키고 Latent Space에서 Random Sampling을 통해 z1을 얻는다.
-
Residual Loss
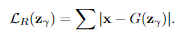
X와 G(z1)을 통해서 나온 Fake Image를 비교한다. 즉, Latent Space에서의 z벡터를 업데이트 하기 위한 Loss이다. -
Discriminator Loss
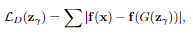
Discriminator을 통한 X의 feature와 G(z)의 feature 차이를 계산하는 Loss이다. -
Total Loss
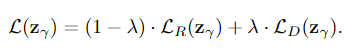
위에서 구한 Residual Loss와 Discriminator Loss의 합으로 Residual Loss에는 1-Lambda, Discriminator Loss에는 Lambda의 가중치를 곱해서 더해준다. (논문에서 Lambda는 0.1을 사용). 아래의 식이 최종적으로 X와 가장 유사한 이미지를 만들어내는 Latent Vector z를 업데이트 할 Loss가 된다.
Anomaly Detection
본 논문에서는 Loss Function 자체를 Anomaly Score로 사용한다. 결과적으로, X가 정상이라면 latent space로 매핑이 잘 되겠지만, X가 비정상이라면 매핑이 제대로 이루어지지 않는다는것이다. Anomaly Score를 구하는 방법은 다음과 같다.
- Ramdom Sampling한 z를 Generator에 입력하여 Fake Image를 생성한다.
- Total Loss를 Generator와 Discriminator의 가중치는 고정시킨 상태로 Gradient Descent(논문에서는 약 500회 반복)과정을 통해서 최소화 시킨다.
- 학습된 z를 Generator에 입력하여 생성된 이미지를 Real Image와 가장 유사하다고 판단하고, 이때의 Anomal Score를 구한다.
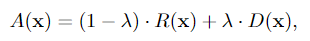
4. t-SNE embedding을 통해 이상과 정상의 분포를 시각화 한다.
Experiments
본 논문에서는 Generator와 Discriminator의 구조는 DCGAN과 동일하지만, 채널의 수는 gray scale것을 감안해 절반으로 줄여서 마지막 출력단에는 3차원이 아닌 1차원으로 사용하였다. 이미지는 64X64 이미지를 사용하였다.
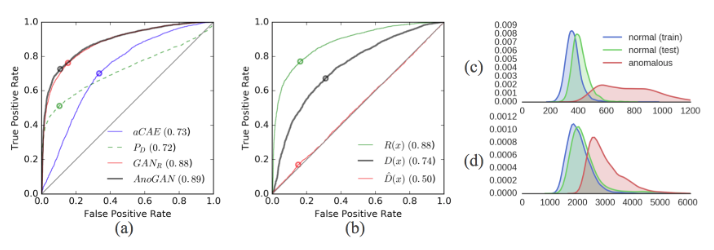
(a)는 a_CAE, GAN_R, AnoGAN, P_D의 ROC커브를 나타낸 것이다. (a)를 보면 GAN_R과 AnoGAN이 가장 좋게 나오는 것을 확인할 수 있다.
(b)는 residual score와 discriminator score, reference discriminator score의 ROC커브를 나타낸 것이다. residual score가 가장 높은 것을 볼 수 있다.
(c)와 (d)는 Residual Score와 Discriminator Score의 분포를 나타낸 것이다. 눈에 보기에도 Residual Score가 정상과 비정상의 분포를 더 명확히 구별하는 것을 알 수 있다.
나만의 요약 및 참고사항
- DCGAN은 Generator를 학습시킬때 Discriminator의 가중치는 업데이트 하지 않고, 반대로 Discriminator를 학습시킬때 Generator의 가중치는 업데이트 하지 않는다.
- AnoGAN은 정상 데이터로만 학습시킨다.
- Residual Loss는 z가 X에 잘 매핑되도록 하는 역할을 한다.(?)
- AnoGAN의 목표는 완성된 모델에 정상/비정상 이미지와(a), 정상데이터의 분포로만 학습된 Latent Space에서 만들어낸 이미지로(b) a와 b를 비교하여 정상 비정상을 판단한다.
댓글남기기