
VAE 코드구현
VAE논문리뷰에서 살펴봤던 것처럼 이번에는 텐서플로우를 이용하여 직접 구현해보도록 하겠다. z를 샘플링하는 task나 loss를 구하는 task는 사진과 함께 설명하겠다!
# Import
from tensorflow.keras import layers,models,datasets,losses
from tensorflow.keras import backend as K
import numpy as np
import matplotlib.pyplot as plt
backend는 keras에서도 tensorflow에서 사용하는 연산기능? 들을 수행할 수 있게 해주는 패키지이다.
# Mnist 데이터셋 로드
(x_train, _), (x_test,_) = datasets.mnist.load_data()
# 정규화 과정
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
# 28X28 이미지를 1차원으로 변경
x_train = x_train.reshape(-1,784)
x_test = x_test.reshape(-1,784)
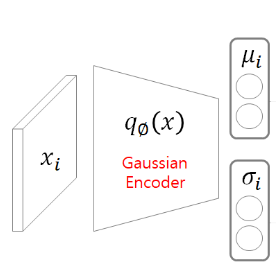
input_shape = (784,)
latent = 2 # latent 차원의 수(논문에서는 2로 했다.)
encoder_input = tf.keras.Input(input_shape)
encoding = layers.Dense(latent, activation='relu')(encoder_input)
# output
mean = layers.Dense(latent)(encoding)
log_var = layers.Dense(latent)(encoding)
사진과 같이 인코더를 통과하면 $\mu$ 와 $\sigma$ 를 output으로 내는 과정이다. $\mu$ 와 $\sigma$ 를 구하는 과정에서 같은 값이 들어가면 $\mu$ 와 $\sigma$의 값이 같게 나오지 않을 까? 라는 생각이 들었는데 다른 Dense layer이고 레이어가 호출될 때, 가중치와 편차는 랜덤으로 초기화 되기 때문에 결국 다른 값이 나온다!
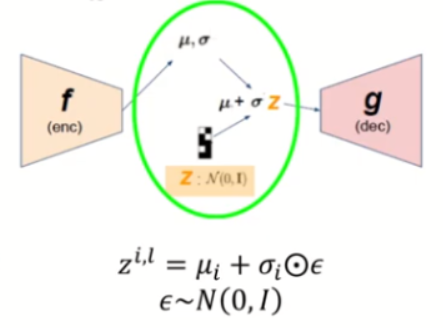
def sampling(data) :
mean,log_var = data
epsilon = K.random_normal(mean=0. ,stddev=1. ,shape=(K.shape(log_var)[0],latent))
return mean + K.exp(log_var/2)* epsilon
sampled = layers.Lambda(sampling,output_shape=(latent,))([mean,log_var])
이 과정은 z를 sampling하는 과정으로, Reparameterization Trick에 해당한다. $\epsilon$ 을 0,1인 정규분포에서 추출해서 계산한다. Lambda레이어는 사용자가 정의한 코드로 layer를 실행할 수 있다. $\mu$ 와 $\sigma$를 input으로 받아서 sampling하는 layer라고 생각하면 된다.
decoder_input = tf.keras.Input((latent,))
decoding = layers.Dense(784,activation='sigmoid')(decoder_input)
# 디코더 모델을 정의
decoder = models.Model(decoder_input,decoding)
# #모델에 샘플링한 모델 입력 사용
decoder = decoder(sampled)
# 인코더와 디코더를 합침
vae = models.Model(encoder_input, decoder)
# Reconstrction Loss
bc_loss = losses.binary_crossentropy(encoder_input,decoder)
# 평균을 내기 위함
bc_loss *= 784
# Regularization Loss
KL_loss = K.mean(1 + log_var - K.square(mean) -K.exp(log_var)) * -0.5
# Total Loss
vae_loss = K.mean(bc_loss + KL_loss)
# 사용자 정의한 loss사용
vae.add_loss(vae_loss)
vae.compile(optimizer='adam',loss=None)
VAE에서 loss는 두개의 합으로 나타내어 진다. 0.5라는 값은 하이퍼파라미터이고 조정가능하다. Reconstrction Loss는 encoder_input과 샘플링한 z를 이용해서 decoder를 통과했을 때 나온 값의 차이를 줄인다. Regularization Loss는 input의 분포와 근사화 한 분포에 대한 차이를 줄인다.
# 학습
vae.fit(x_train,None,shuffle=True,epochs=30,validation_data=(x_test, None))
Epoch 1/30
1875/1875 [==============================] - 4s 2ms/step - loss: 459.8037 - val_loss: 403.4405
Epoch 10/30
1875/1875 [==============================] - 3s 2ms/step - loss: 356.9845 - val_loss: 354.9610
Epoch 20/30
1875/1875 [==============================] - 3s 2ms/step - loss: 355.0828 - val_loss: 353.0179
Epoch 30/30
1875/1875 [==============================] - 3s 2ms/step - loss: 354.6214 - val_loss: 352.4473
# decoding한 이미지
decoded_imgs = vae.predict(x_train)
1875/1875 [==============================] - 2s 822us/step
# 결과
n = 10 # 이미지 갯수
plt.figure(figsize=(20, 4))
for i in range(1, n+1):
# 원본 데이터
ax = plt.subplot(2, n, i)
plt.imshow(x_train[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 재구성된 데이터
ax = plt.subplot(2, n, i + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()

오늘의 정리
30에폭으로 돌린 결과인데 그다지 썩 좋지는 않은 것 같다. 아무래도 Dense layer만 사용하고 1차원 데이터로 사용해서 그런 것 같다. 좋은 결과를 얻기 위해서 에폭을 늘리고 컨볼루션 VAE를 사용하면 될 것 같다.
댓글남기기