
DDPM 코드 구현
본 포스팅은 DDPM을 구현합니다. DDPM에 대해서 모르시는 분들은 여기 참고해주세요.
환경 설정
- cudatoolkit==11.0.3
- cudnn==8.0.5.39
- tensorflow==2.4.0
- tensorflow_addons==0.16.1
- tensorflow_datasets==4.7.0
Import
import os
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
from PIL import Image
import tensorflow as tf
from tensorflow import keras, einsum
from tensorflow.keras import Model, Sequential
from tensorflow.keras.layers import Layer, LayerNormalization
import tensorflow.keras.layers as nn
import tensorflow_addons as tfa
import tensorflow_datasets as tfds
import inspect
from einops import rearrange
from functools import partial
# Suppressing tf.hub warnings
tf.get_logger().setLevel("ERROR")
# configure the GPU
gpu_options = tf.compat.v1.GPUOptions(per_process_gpu_memory_fraction=0.8)
config = tf.compat.v1.ConfigProto(gpu_options=gpu_options)
session = tf.compat.v1.Session(config=config)
hyperparameter 지정
target_size = (32, 32)
channels = 1
timesteps = 200
BATCH_SIZE=64
tfds를 이용하여 Mnist 불러오기 및 전처리
# 정규화 함수
def preprocess(x, y):
return tf.image.resize(tf.cast(x, tf.float32) / 127.5 - 1, target_size)
def get_datasets():
# Mnist 데이터셋 로드
train_ds = tfds.load('mnist', as_supervised=True, split="train")
# 데이터 정규화
train_ds = train_ds.map(preprocess, tf.data.AUTOTUNE)
# 데이터 셔플 및 배치화
train_ds = train_ds.shuffle(5000).batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
# tensor대신 numpy 배열로 변환 -> iter가능
return tfds.as_numpy(train_ds)
train_ds = get_datasets()
sample_mnist = next(iter(train_ds))
print(sample_mnist.shape)
(64, 32, 32, 1)
2023-01-23 14:12:03.862633: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
베타 스케쥴링
# 베타 스케쥴링
beta = np.linspace(0.0001, 0.02, timesteps)
Reparameterization trick
- backpropagation을 가능하게 해줌
alpha = 1 - beta
alpha_bar = np.cumprod(alpha, 0)
alpha_bar = np.concatenate((np.array([1.]), alpha_bar[:-1]), axis=0)
sqrt_alpha_bar = np.sqrt(alpha_bar)
one_minus_sqrt_alpha_bar = np.sqrt(1-alpha_bar)
시드설정, 노이즈 추가, timestamp 생성 함수
- 노이즈 추가는 forward process에 해당
# 시드 설정
def set_key(key):
np.random.seed(key)
# timestamp 마다 점진적으로 noise 추가하는 함수
def forward_noise(key, x_0, t):
set_key(key)
noise = np.random.normal(size=x_0.shape) # (1, 32, 32, 1)
reshaped_sqrt_alpha_bar_t = np.reshape(np.take(sqrt_alpha_bar, t), (-1, 1, 1, 1)) # (1, 1, 1, 1)
reshaped_one_minus_sqrt_alpha_bar_t = np.reshape(np.take(one_minus_sqrt_alpha_bar, t), (-1, 1, 1, 1)) # (1, 1, 1, 1)
noisy_image = reshaped_sqrt_alpha_bar_t * x_0 + reshaped_one_minus_sqrt_alpha_bar_t * noise # (1, 32, 32, 1)
return noisy_image, noise
# 0 & T 사이의 timestamp 생성하는 함수
def generate_timestamp(key, num):
set_key(key)
return tf.random.uniform(shape=[num], minval=0, maxval=timesteps, dtype=tf.int32)
노이즈 이미지 출력
sample_mnist = next(iter(train_ds))[2]
print(sample_mnist.shape)
fig = plt.figure(figsize=(15, 30))
for index, i in enumerate([i for i in range(0, 200, 20)]):
noisy_im, noise = forward_noise(0, np.expand_dims(sample_mnist, 0), np.array([i,]))
plt.subplot(1, 10, index+1)
plt.imshow(noisy_im.reshape(target_size), cmap='gray')
plt.show()
2023-01-23 14:12:14.549663: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
(32, 32, 1)

U-Net 모델
import math
def exists(x):
return x is not None
def default(val, d):
if exists(val):
return val
return d() if inspect.isfunction(d) else d
class SinusoidalPosEmb(Layer):
def __init__(self, dim, max_positions=10000):
super(SinusoidalPosEmb, self).__init__()
self.dim = dim
self.max_positions = max_positions
def call(self, x, training=True):
x = tf.cast(x, tf.float32)
half_dim = self.dim // 2
emb = math.log(self.max_positions) / (half_dim - 1)
emb = tf.exp(tf.range(half_dim, dtype=tf.float32) * -emb)
emb = x[:, None] * emb[None, :]
emb = tf.concat([tf.sin(emb), tf.cos(emb)], axis=-1)
return emb
# small helper modules
class Identity(Layer):
def __init__(self):
super(Identity, self).__init__()
def call(self, x, training=True):
return tf.identity(x)
class Residual(Layer):
def __init__(self, fn):
super(Residual, self).__init__()
self.fn = fn
def call(self, x, training=True):
return self.fn(x, training=training) + x
def Upsample(dim):
return nn.Conv2DTranspose(filters=dim, kernel_size=4, strides=2, padding='SAME')
def Downsample(dim):
return nn.Conv2D(filters=dim, kernel_size=4, strides=2, padding='SAME')
class PreNorm(Layer):
def __init__(self, dim, fn):
super(PreNorm, self).__init__()
self.fn = fn
self.norm = LayerNormalization(-1)
def call(self, x, training=True):
x = self.norm(x)
return self.fn(x)
class SiLU(Layer):
def __init__(self):
super(SiLU, self).__init__()
def call(self, x, training=True):
return x * tf.nn.sigmoid(x)
def gelu(x, approximate=False):
if approximate:
coeff = tf.cast(0.044715, x.dtype)
return 0.5 * x * (1.0 + tf.tanh(0.7978845608028654 * (x + coeff * tf.pow(x, 3))))
else:
return 0.5 * x * (1.0 + tf.math.erf(x / tf.cast(1.4142135623730951, x.dtype)))
class GELU(Layer):
def __init__(self, approximate=False):
super(GELU, self).__init__()
self.approximate = approximate
def call(self, x, training=True):
return gelu(x, self.approximate)
# building block modules
class Block(Layer):
def __init__(self, dim, groups=8):
super(Block, self).__init__()
self.proj = nn.Conv2D(dim, kernel_size=3, strides=1, padding='SAME')
self.norm = tfa.layers.GroupNormalization(groups, epsilon=1e-05)
self.act = SiLU()
def call(self, x, gamma_beta=None, training=True):
x = self.proj(x)
x = self.norm(x, training=training)
if exists(gamma_beta):
gamma, beta = gamma_beta
x = x * (gamma + 1) + beta
x = self.act(x)
return x
class ResnetBlock(Layer):
def __init__(self, dim, dim_out, time_emb_dim=None, groups=8):
super(ResnetBlock, self).__init__()
self.mlp = Sequential([
SiLU(),
nn.Dense(units=dim_out * 2)
]) if exists(time_emb_dim) else None
self.block1 = Block(dim_out, groups=groups)
self.block2 = Block(dim_out, groups=groups)
self.res_conv = nn.Conv2D(filters=dim_out, kernel_size=1, strides=1) if dim != dim_out else Identity()
def call(self, x, time_emb=None, training=True):
gamma_beta = None
if exists(self.mlp) and exists(time_emb):
time_emb = self.mlp(time_emb)
time_emb = rearrange(time_emb, 'b c -> b 1 1 c')
gamma_beta = tf.split(time_emb, num_or_size_splits=2, axis=-1)
h = self.block1(x, gamma_beta=gamma_beta, training=training)
h = self.block2(h, training=training)
return h + self.res_conv(x)
class LinearAttention(Layer):
def __init__(self, dim, heads=4, dim_head=32):
super(LinearAttention, self).__init__()
self.scale = dim_head ** -0.5
self.heads = heads
self.hidden_dim = dim_head * heads
self.attend = nn.Softmax()
self.to_qkv = nn.Conv2D(filters=self.hidden_dim * 3, kernel_size=1, strides=1, use_bias=False)
self.to_out = Sequential([
nn.Conv2D(filters=dim, kernel_size=1, strides=1),
LayerNormalization(-1)
])
def call(self, x, training=True):
b, h, w, c = x.shape
qkv = self.to_qkv(x)
qkv = tf.split(qkv, num_or_size_splits=3, axis=-1)
q, k, v = map(lambda t: rearrange(t, 'b x y (h c) -> b h c (x y)', h=self.heads), qkv)
q = tf.nn.softmax(q, axis=-2)
k = tf.nn.softmax(k, axis=-1)
q = q * self.scale
context = einsum('b h d n, b h e n -> b h d e', k, v)
out = einsum('b h d e, b h d n -> b h e n', context, q)
out = rearrange(out, 'b h c (x y) -> b x y (h c)', h=self.heads, x=h, y=w)
out = self.to_out(out, training=training)
return out
class Attention(Layer):
def __init__(self, dim, heads=4, dim_head=32):
super(Attention, self).__init__()
self.scale = dim_head ** -0.5
self.heads = heads
self.hidden_dim = dim_head * heads
self.to_qkv = nn.Conv2D(filters=self.hidden_dim * 3, kernel_size=1, strides=1, use_bias=False)
self.to_out = nn.Conv2D(filters=dim, kernel_size=1, strides=1)
def call(self, x, training=True):
b, h, w, c = x.shape
qkv = self.to_qkv(x)
qkv = tf.split(qkv, num_or_size_splits=3, axis=-1)
q, k, v = map(lambda t: rearrange(t, 'b x y (h c) -> b h c (x y)', h=self.heads), qkv)
q = q * self.scale
sim = einsum('b h d i, b h d j -> b h i j', q, k)
sim_max = tf.stop_gradient(tf.expand_dims(tf.argmax(sim, axis=-1), axis=-1))
sim_max = tf.cast(sim_max, tf.float32)
sim = sim - sim_max
attn = tf.nn.softmax(sim, axis=-1)
out = einsum('b h i j, b h d j -> b h i d', attn, v)
out = rearrange(out, 'b h (x y) d -> b x y (h d)', x = h, y = w)
out = self.to_out(out, training=training)
return out
class Unet(Model):
def __init__(self,
dim=64,
init_dim=None,
out_dim=None,
dim_mults=(1, 2, 4, 8),
channels=3,
resnet_block_groups=8,
learned_variance=False,
sinusoidal_cond_mlp=True
):
super(Unet, self).__init__()
# determine dimensions
self.channels = channels
init_dim = default(init_dim, dim // 3 * 2)
self.init_conv = nn.Conv2D(filters=init_dim, kernel_size=7, strides=1, padding='SAME')
dims = [init_dim, *map(lambda m: dim * m, dim_mults)]
in_out = list(zip(dims[:-1], dims[1:]))
block_klass = partial(ResnetBlock, groups = resnet_block_groups)
# time embeddings
time_dim = dim * 4
self.sinusoidal_cond_mlp = sinusoidal_cond_mlp
self.time_mlp = Sequential([
SinusoidalPosEmb(dim),
nn.Dense(units=time_dim),
GELU(),
nn.Dense(units=time_dim)
], name="time embeddings")
# layers
self.downs = []
self.ups = []
num_resolutions = len(in_out)
for ind, (dim_in, dim_out) in enumerate(in_out):
is_last = ind >= (num_resolutions - 1)
self.downs.append([
block_klass(dim_in, dim_out, time_emb_dim=time_dim),
block_klass(dim_out, dim_out, time_emb_dim=time_dim),
Residual(PreNorm(dim_out, LinearAttention(dim_out))),
Downsample(dim_out) if not is_last else Identity()
])
mid_dim = dims[-1]
self.mid_block1 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)
self.mid_attn = Residual(PreNorm(mid_dim, Attention(mid_dim)))
self.mid_block2 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)
for ind, (dim_in, dim_out) in enumerate(reversed(in_out[1:])):
is_last = ind >= (num_resolutions - 1)
self.ups.append([
block_klass(dim_out * 2, dim_in, time_emb_dim=time_dim),
block_klass(dim_in, dim_in, time_emb_dim=time_dim),
Residual(PreNorm(dim_in, LinearAttention(dim_in))),
Upsample(dim_in) if not is_last else Identity()
])
default_out_dim = channels * (1 if not learned_variance else 2)
self.out_dim = default(out_dim, default_out_dim)
self.final_conv = Sequential([
block_klass(dim * 2, dim),
nn.Conv2D(filters=self.out_dim, kernel_size=1, strides=1)
], name="output")
def call(self, x, time=None, training=True, **kwargs):
x = self.init_conv(x)
t = self.time_mlp(time)
h = []
for block1, block2, attn, downsample in self.downs:
x = block1(x, t)
x = block2(x, t)
x = attn(x)
h.append(x)
x = downsample(x)
x = self.mid_block1(x, t)
x = self.mid_attn(x)
x = self.mid_block2(x, t)
for block1, block2, attn, upsample in self.ups:
x = tf.concat([x, h.pop()], axis=-1)
x = block1(x, t)
x = block2(x, t)
x = attn(x)
x = upsample(x)
x = tf.concat([x, h.pop()], axis=-1)
x = self.final_conv(x)
return x
체크포인트 저장 및 불러오기
# unet model 생성
unet = Unet(channels=1)
# checkpoinmanager 생성
ckpt = tf.train.Checkpoint(unet=unet)
ckpt_manager = tf.train.CheckpointManager(ckpt, "./mnist", max_to_keep=2)
# 이전 체크포인트가 존재하면 load함
if ckpt_manager.latest_checkpoint:
ckpt.restore(ckpt_manager.latest_checkpoint)
start_interation = int(ckpt_manager.latest_checkpoint.split("-")[-1])
print("체크포인트 로드 {}".format(ckpt_manager.latest_checkpoint))
else:
print("체크포인트 초기화")
# 모델 initialize
test_images = np.ones([1, 32, 32, 1])
test_timestamps = generate_timestamp(0, 1)
unet(test_images, test_timestamps)
# 옵티마이저 정의
opt = keras.optimizers.Adam(learning_rate=1e-4)
체크포인트 초기화
손실함수 정의
def loss_fn(real, generated):
loss = tf.math.reduce_mean((real - generated) ** 2)
return loss
학습
rng = 0
def train_step(batch):
rng, tsrng = np.random.randint(0, 100000, size=(2,))
# timestamp 및 노이즈 생성을 위한 난수 생성
timestep_values = generate_timestamp(tsrng, batch.shape[0])
# 배치 크기에 따라 임의의 timestamp 목록 생성
noised_image, noise = forward_noise(rng, batch, timestep_values)
# timestamp와 함께 이미지 노이즈 추가
with tf.GradientTape() as tape:
prediction = unet(noised_image, timestep_values)
# 노이즈 이미지와 timestamp를 사용하여 Unet에서 모델 예측
loss_value = loss_fn(noise, prediction)
# 손실 계산
gradients = tape.gradient(loss_value, unet.trainable_variables)
opt.apply_gradients(zip(gradients, unet.trainable_variables))
# 모델에서 훈련가능한 변수를 업데이트함
return loss_value
epochs = 30
for e in range(1, epochs+1):
# this is cool utility in Tensorflow that will create a nice looking progress bar
bar = tf.keras.utils.Progbar(len(train_ds)-1)
losses = []
for i, batch in enumerate(iter(train_ds)): # i=937, batch=(64, 32, 32, 1)
# run the training loop
loss = train_step(batch)
losses.append(loss)
bar.update(i, values=[("loss", loss)])
avg = np.mean(losses)
print(f"Average loss for epoch {e}/{epochs}: {avg}")
ckpt_manager.save(checkpoint_number=e)
937/937 [==============================] - 250s 265ms/step - loss: 0.2981
Average loss for epoch 1/30: 0.2981025278568268
937/937 [==============================] - 251s 267ms/step - loss: 0.0954
Average loss for epoch 2/30: 0.09544883668422699
937/937 [==============================] - 251s 267ms/step - loss: 0.0730
Average loss for epoch 3/30: 0.07301818579435349
937/937 [==============================] - 250s 267ms/step - loss: 0.0649
Average loss for epoch 4/30: 0.06492534279823303
937/937 [==============================] - 252s 269ms/step - loss: 0.0596
Average loss for epoch 5/30: 0.05961119756102562
937/937 [==============================] - 251s 267ms/step - loss: 0.0566
Average loss for epoch 6/30: 0.05659157410264015
937/937 [==============================] - 250s 267ms/step - loss: 0.0532
Average loss for epoch 7/30: 0.053236108273267746
937/937 [==============================] - 250s 267ms/step - loss: 0.0505
Average loss for epoch 8/30: 0.05048508569598198
937/937 [==============================] - 250s 267ms/step - loss: 0.0480
Average loss for epoch 9/30: 0.048006322234869
937/937 [==============================] - 251s 267ms/step - loss: 0.0465
Average loss for epoch 10/30: 0.0465264730155468
937/937 [==============================] - 251s 268ms/step - loss: 0.0444
Average loss for epoch 11/30: 0.04440772160887718
937/937 [==============================] - 252s 268ms/step - loss: 0.0426
Average loss for epoch 12/30: 0.04260953515768051
937/937 [==============================] - 250s 266ms/step - loss: 0.0425
Average loss for epoch 13/30: 0.042479705065488815
937/937 [==============================] - 250s 266ms/step - loss: 0.0413
Average loss for epoch 14/30: 0.041292235255241394
937/937 [==============================] - 251s 267ms/step - loss: 0.0406
Average loss for epoch 15/30: 0.040558625012636185
937/937 [==============================] - 251s 268ms/step - loss: 0.0402
Average loss for epoch 16/30: 0.040178295224905014
937/937 [==============================] - 252s 268ms/step - loss: 0.0398
Average loss for epoch 17/30: 0.039778534322977066
937/937 [==============================] - 252s 269ms/step - loss: 0.0393
Average loss for epoch 18/30: 0.039348505437374115
937/937 [==============================] - 252s 268ms/step - loss: 0.0390
Average loss for epoch 19/30: 0.03896510601043701
937/937 [==============================] - 249s 265ms/step - loss: 0.0385
Average loss for epoch 20/30: 0.03849511221051216
937/937 [==============================] - 250s 266ms/step - loss: 0.0379
Average loss for epoch 21/30: 0.03791522607207298
937/937 [==============================] - 249s 265ms/step - loss: 0.0378
Average loss for epoch 22/30: 0.03778776898980141
937/937 [==============================] - 250s 266ms/step - loss: 0.0379
Average loss for epoch 23/30: 0.037863846868276596
937/937 [==============================] - 250s 266ms/step - loss: 0.0375
Average loss for epoch 24/30: 0.03746611997485161
937/937 [==============================] - 250s 267ms/step - loss: 0.0366
Average loss for epoch 25/30: 0.03662267327308655
937/937 [==============================] - 250s 266ms/step - loss: 0.0367
Average loss for epoch 26/30: 0.036681391298770905
937/937 [==============================] - 251s 267ms/step - loss: 0.0366
Average loss for epoch 27/30: 0.036597684025764465
937/937 [==============================] - 250s 266ms/step - loss: 0.0363
Average loss for epoch 28/30: 0.03628880903124809
937/937 [==============================] - 250s 267ms/step - loss: 0.0360
Average loss for epoch 29/30: 0.03601287677884102
937/937 [==============================] - 250s 266ms/step - loss: 0.0364
Average loss for epoch 30/30: 0.03636723384261131
gif 함수
def save_gif(img_list, path="", interval=100):
# Transform images from [-1,1] to [0, 255]
imgs = []
for im in img_list:
im = np.array(im)
im = (im + 1) * 127.5
im = np.clip(im, 0, 255).astype(np.int32)
im = Image.fromarray(im)
imgs.append(im)
imgs = iter(imgs)
# Extract first image from iterator
img = next(imgs)
# Append the other images and save as GIF
img.save(fp=path, format='GIF', append_images=imgs,
save_all=True, duration=interval, loop=0)
DDPM을 이용한 추론
def ddpm(x_t, pred_noise, t):
alpha_t = np.take(alpha, t)
alpha_t_bar = np.take(alpha_bar, t)
eps_coef = (1 - alpha_t) / (1 - alpha_t_bar) ** .5
mean = (1 / (alpha_t ** .5)) * (x_t - eps_coef * pred_noise)
var = np.take(beta, t)
z = np.random.normal(size=x_t.shape)
return mean + (var ** .5) * z
x = tf.random.normal((1,32,32,1))
img_list = []
img_list.append(np.squeeze(np.squeeze(x, 0),-1))
for i in tqdm(range(timesteps-1)):
t = np.expand_dims(np.array(timesteps-i-1, np.int32), 0)
pred_noise = unet(x, t)
x = ddpm(x, pred_noise, t)
img_list.append(np.squeeze(np.squeeze(x, 0),-1))
if i % 25==0:
plt.imshow(np.array(np.clip((x[0] + 1) * 127.5, 0, 255), np.uint8), cmap="gray")
save_gif(img_list + ([img_list[-1]] * 100), "ddpm.gif", interval=10)
plt.imshow(np.array(np.clip((x[0] + 1) * 127.5, 0, 255), np.uint8))
plt.show()
100%|██████████| 199/199 [00:22<00:00, 8.80it/s]
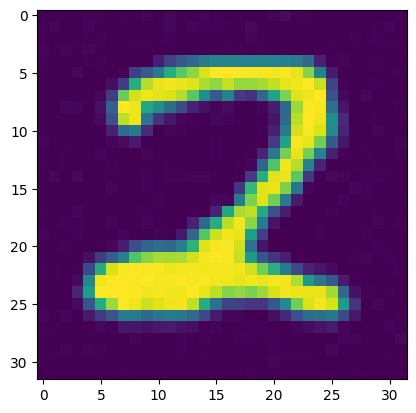

DDIM을 이용한 추론
- Markov chain의 이전 순서가 이전 이미지에 의존해야 한다는 제약 조건을 제거
- 추론시간이 빠름
def ddim(x_t, pred_noise, t, sigma_t):
alpha_t_bar = np.take(alpha_bar, t)
alpha_t_minus_one = np.take(alpha, t-1)
pred = (x_t - ((1 - alpha_t_bar) ** 0.5) * pred_noise)/ (alpha_t_bar ** 0.5)
pred = (alpha_t_minus_one ** 0.5) * pred
pred = pred + ((1 - alpha_t_minus_one - (sigma_t ** 2)) ** 0.5) * pred_noise
eps_t = np.random.normal(size=x_t.shape)
pred = pred+(sigma_t * eps_t)
return pred
inference_timesteps = 10
# Create a range of inference steps that the output should be sampled at
inference_range = range(0, timesteps, timesteps // inference_timesteps)
x = tf.random.normal((1,32,32,1))
img_list = []
img_list.append(np.squeeze(np.squeeze(x, 0),-1))
# Iterate over inference_timesteps
for index, i in tqdm(enumerate(reversed(range(inference_timesteps))), total=inference_timesteps):
t = np.expand_dims(inference_range[i], 0)
pred_noise = unet(x, t)
x = ddim(x, pred_noise, t, 0)
img_list.append(np.squeeze(np.squeeze(x, 0),-1))
if index % 1 == 0:
plt.imshow(np.array(np.clip((np.squeeze(np.squeeze(x, 0),-1) + 1) * 127.5, 0, 255), np.uint8), cmap="gray")
save_gif(img_list + ([img_list[-1]] * 100), "ddim.gif", interval=300)
plt.imshow(np.array(np.clip((x[0] + 1) * 127.5, 0, 255), np.uint8), cmap="gray")
plt.show()
100%|██████████| 10/10 [00:01<00:00, 8.85it/s]
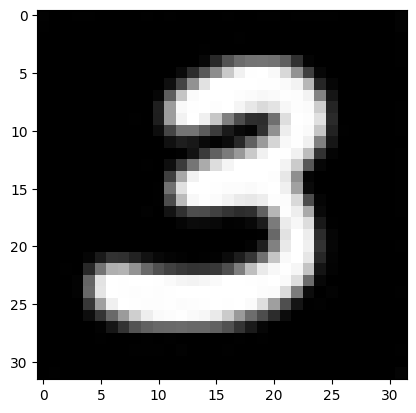

오늘의 정리
Mnist의 shape은 28x28 이미지 이지만 input으로 넣을 때 32x32로 넣는다. 왜 32x32로 들어가는지 모르겠다..다음번에는 DDPM에서 몇가지 문제점을 수정한 DDIM에 대해서 포스팅 해봐야겠다.
댓글남기기